Google DeepMind 开发了一种创新的的视频编辑技术方法:Generative OmniMatte […]
Anthropic 发布了 Model Context Protocol (MCP),一个旨在将 AI 助手与 […]
OminiControl 是一个为 FLUX.1 模型 设计的简单而通用的控制框架,由新加坡国立大学的学习与视 […]
NVIDIA 发布了一款音乐生成人工智能模型:Fugatto。通过简单的文本提示或音频输入,用户可以创作全新的 […]
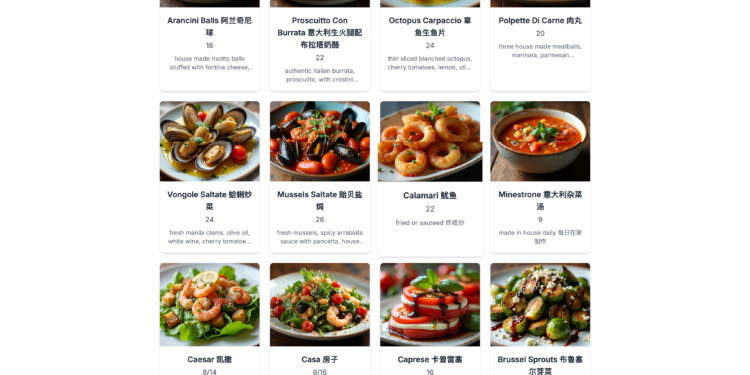
PicMenu 是一个利用 AI 快速将餐厅菜单可视化的工具。通过拍摄菜单图片,PicMenu 可以为每道菜生 […]
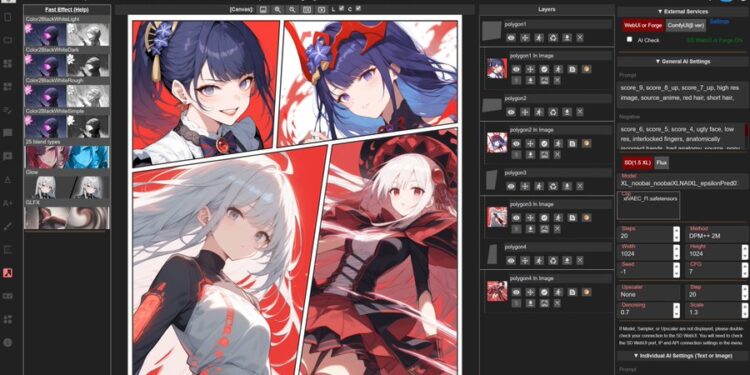
SP-MangaEditor 是一个专门用来制作漫画的网页应用,可运行在你的浏览器里。它提供了很多专业工具,比 […]
SAMURAI:基于Segment Anything Model 2 (SAM 2) 改进的视觉对象跟踪模型, […]
Runway 推出了最新的图像生成模型 Frames,该模型以卓越的风格一致性和视觉真实感为特色,为创作者提供 […]
OOTDiffusion 是一个基于扩散模型(Latent Diffusion)的虚拟试穿系统。它使用先进的服 […]
支付宝发布 EchoMimicV2 ,从仅支持头部驱动的动画扩展到 半身动画(包括头部、手势和上身动作)。 支 […]
Runway 推出的一项创新视频编辑工具:Expand Video 。能够无缝转换横向视频为竖向视频,反之亦然 […]
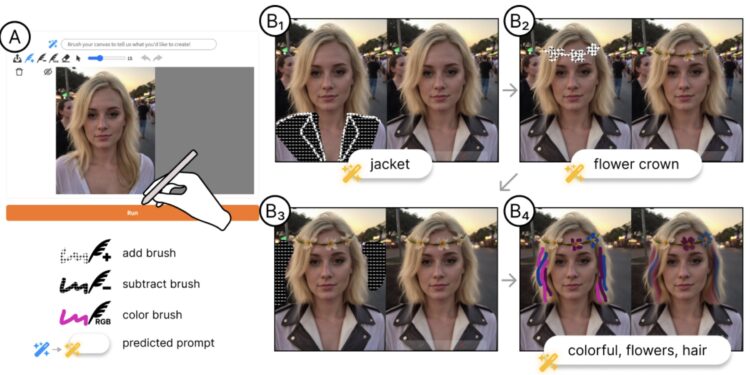
MagicQuill 是由支付宝和香港大学联合开发的一个功能强大的智能互动图像编辑系统,通过直观的界面和 AI […]
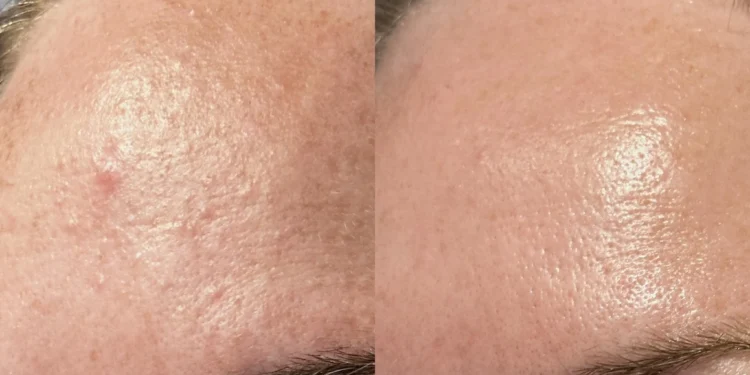
通过 Stable Diffusion 和相关工具实现一致性穿衣模型与工作流的创新方法,可以将实物服装精确地迁 […]
GetPickle.ai 是一款致力于革新虚拟会议体验的AI工具,其核心技术通过提供高度逼真的AI克隆化身,使 […]
Stripe Agent Toolkit 是专为将财务功能集成到 AI 代理中的 SDK。它允许开发者通过函数 […]
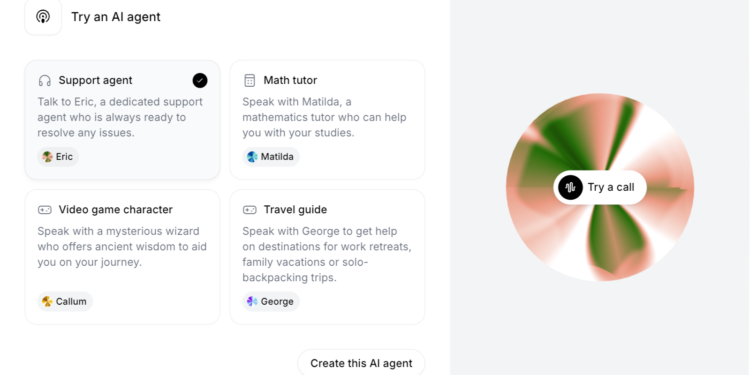
ElevenLabs 宣布其开发者平台新增了创建对话式AI代理的功能。 这项新功能允许开发者平台上构建对话式A […]
“人红是非多”,明星大模型独角兽月之暗面又“摊上事”了。 据暗涌报道,Kimi背后公司月之暗面的创始人& […]
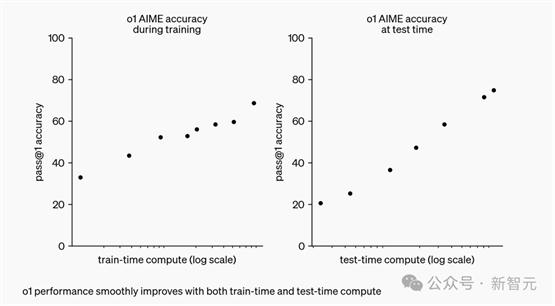
Ilya终于承认,自己关于Scaling的说法错了!现在训练模型已经不是「越大越好」,而是找出Scaling的 […]
FLUX 1.1 Pro Ultra 发布,支持高达 4 兆像素的分辨率,并具有快速生成速度,每张图片仅需约 […]
上周Runway 推出了一款生成式角色表演工具,可以把视频转换成任意风格虚拟角色动画,并且保持表情语音口型同步 […]
苹果正式推出集成Siri 和 Apple Intelligence新框架:App Intents ,允许开发者 […]
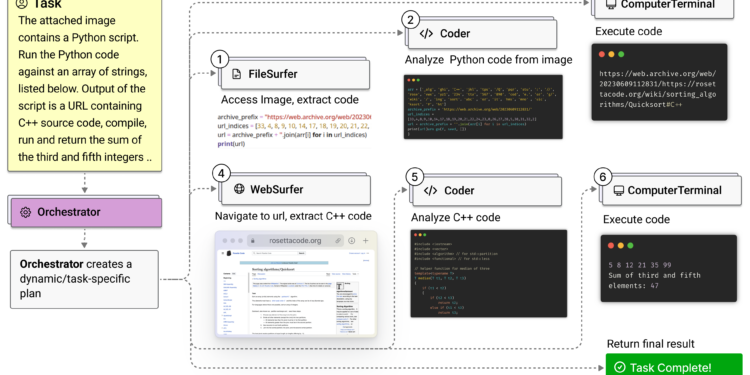
微软研究团队推出了 Magentic-One,一个通用的多智能体系统,具备在不同领域中处理开放性任务的能力。该 […]
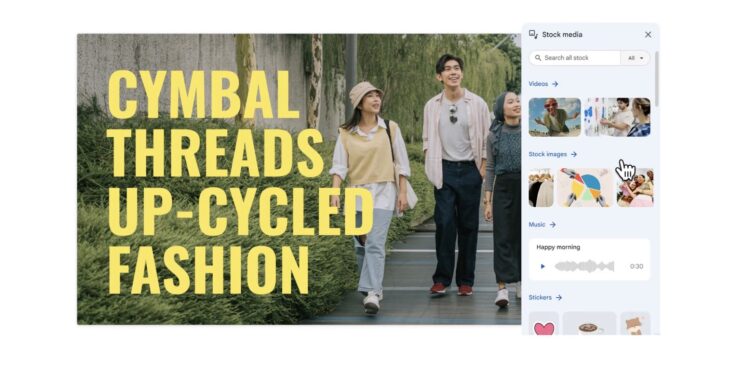
Google 正式推出了其 Gemini AI 驱动的视频演示应用程序 Vids,用户可以通过简单的提示生成视 […]
NVIDIA 推出的 AI Blueprint , 这是一套用于构建视觉AI代理的框架,帮助开发者构建视频理解 […]
Reddit 用户 General-Implement83 分享了她如何使用 ChatGPT 定制了一个个性化 […]
SeedEdit 是一个AI图像编辑工具,由 Doubao 团队开发。它的特殊之处在于,可以根据用户输入的文字 […]
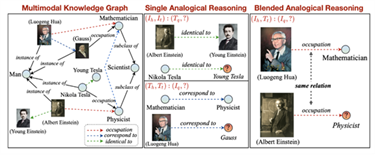
多模态推理多模态推理涉及至少两种不同的感知模态,最常见的是视觉和语言。这两种模态的信息可以是图片和文本、视频和 […]
PDF 文件作为一种广泛使用的文档格式,包含着大量有价值的信息。然而,从 PDF 中高效、准确地提取信息一直是 […]
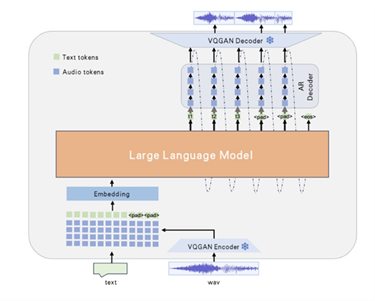
在当今数字化时代,人工智能技术正以前所未有的速度发展,深刻地改变着我们的生活和工作方式。语音交互作为人机交互的 […]
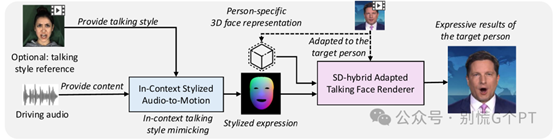
随着数字人技术的发展,生成高度逼真的「3D说话头像」(3D Talking Face)成为了一种趋势。这不仅对 […]

















Google DeepMind 开发了一种创新的的视频编辑技术方法:Generative OmniMatte […]