AIGC系列之一-一文理解什么是Embedding嵌入技术
发布时间:2024年07月17日
摘要:嵌入技术(Embedding)是一种将高维数据映射到低维空间的技术,在人工智能与图形学研究中被广泛应用。本文将介绍嵌入技术的基本概念、原理以及在 AIGC(Artificial Intelligence and Graphics Computing)和实际应用场景中的应用。
·
什么是Embedding
·
原理是什么
·
有哪些应用场景
![]()
01
—
什么是Embedding
Embedding模型是一种在机器学习和自然语言处理中广泛应用的技术,它旨在将高维度的数据(如文字、图片、视频等)映射到低维度的空间。Embedding向量是一个N维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。这种嵌入可以是一个词、一个类别特征(如商品、电影、物品等)或时间序列特征等。通过学习,Embedding向量可以更准确地表示对应特征的内在含义,使几何距离相近的向量对应的物体有相近的含义。Embedding层往往是神经网络的第一层,它可以训练,可以学习到对应特征的内在关系。一个模型学习到的Embedding,也可以被其他模型重用。Embedding的目标是在大数据中体现相关性的主体,通过Embedding向量表征学习到主体的向量信息,使用向量度量公式也能体现出主体间的相关性。
使用通俗易懂的语言来表达embedding技术,是使用一种模型生成方法,将非结构化的数据,例如文本、图片、视频等数据映射成向量数据,向量都是由数值表达的向量,向量可以被计算机直接处理。同时,生成的向量还可以表达事物本身的关联性和特征,例如图片的相关性,语意相关性等。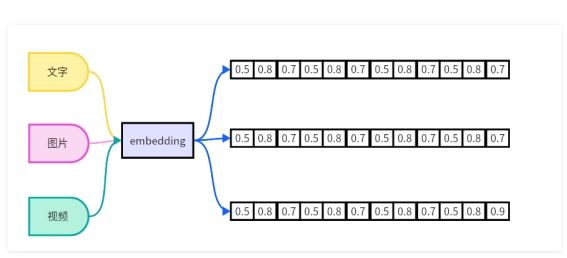
如上图所示,目前生成embeding方法的模型有如下几类:
1、Word2Vec:
Word2Vec 是一种词嵌入(Word Embedding)模型,是嵌入技术在自然语言处理中的一个典型应用。这个模型通过学习将单词转化为连续的向量表示,以便计算机更好地理解和处理文本。Word2Vec 模型基于两种主要算法:CBOW(Continuous Bag of Words)和 Skip-gram。CBOW 模型根据上下文单词预测目标单词,而 Skip-gram 模型则根据目标单词预测上下文单词。通过训练模型,可以得到每个单词的向量表示,这些向量具有一定的语义信息,能够反映单词之间的相似性和差异性。
2、GloVe:
GloVe(Global Vectors for Word Representation)是一种用于自然语言处理的词嵌入模型,它与其他常见的词嵌入模型(如Word2Vec和FastText)类似,可以将单词转化为连续的向量表示。
GloVe模型的原理是通过观察单词在语料库中的共现关系,学习得到单词之间的语义关系。具体来说,GloVe模型将共现概率矩阵表示为两个词向量之间的点积和偏差的关系,然后通过迭代优化来训练得到最佳的词向量表示。
GloVe模型的优点是它能够在大规模语料库上进行有损压缩,得到较小维度的词向量,同时保持了单词之间的语义关系。这些词向量可以被用于多种自然语言处理任务,如词义相似度计算、情感分析、文本分类等。
3、FastText:
FastText是一种基于词袋模型的词嵌入技术,与其他常见的词嵌入模型(如Word2Vec和GloVe)不同之处在于,FastText考虑了单词的子词信息。
FastText的核心思想是将单词视为字符的n-grams的集合,在训练过程中,模型会同时学习单词级别和n-gram级别的表示。这样可以捕捉到单词内部的细粒度信息,从而更好地处理各种形态和变体的单词。
与其他模型相比,FastText的优势在于它能够处理未登录词(Out-of-Vocabulary)和稀疏词,因为它可以通过子词信息对这些词进行建模。另外,FastText还能够处理各种语言的文本数据,并且具有快速训练和推断速度的优势。
4、大模型的 Embeddings:如OpenAI官方发布的 第二代模型:text-embedding-ada-002。它最长的输入是8191个tokens,输出的维度是1536。
Embedding 的价值
1、降维: 在许多实际问题中,原始数据的维度往往非常高。例如,在自然语言处理中,如果使用One-hot编码来表示词汇,其维度等于词汇表的大小,可能达到数十万甚至更高。通过Embedding,我们可以将这些高维数据映射到一个低维空间,大大减少了模型的复杂度。
2、捕捉语义信息: Embedding不仅仅是降维,更重要的是,它能够捕捉到数据的语义信息。例如,在词嵌入中,语义上相近的词在向量空间中也会相近。这意味着Embedding可以保留并利用原始数据的一些重要信息。
3、适应性: 与一些传统的特征提取方法相比,Embedding是通过数据驱动的方式学习的。这意味着它能够自动适应数据的特性,而无需人工设计特征。
4、泛化能力: 在实际问题中,我们经常需要处理一些在训练数据中没有出现过的数据。由于Embedding能够捕捉到数据的一些内在规律,因此对于这些未见过的数据,Embedding仍然能够给出合理的表示。
5、可解释性: 尽管Embedding是高维的,但我们可以通过一些可视化工具(如t-SNE)来观察和理解Embedding的结构。这对于理解模型的行为,以及发现数据的一些潜在规律是非常有用的。
![]()
02
—
原理是什么
为了更好理解embedding的原理我们来以GloVe 来说明详细过程
1、这是一个单词“king”的词嵌入(在维基百科上训练的GloVe向量)得到的结果是:
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
2、这是一个包含50个数字的列表。通过观察数值我们看不出什么,但是让我们稍微给它可视化,以便比较其它词向量。我们把所有这些数字放在一行:
![]()
3、让我们根据它们的值对单元格进行颜色编码(如果它们接近2则为红色,接近0则为白色,接近-2则为蓝色):

4、我们将忽略数字并仅查看颜色以指示单元格的值。现在让我们将“king”与其它单词进行比较:
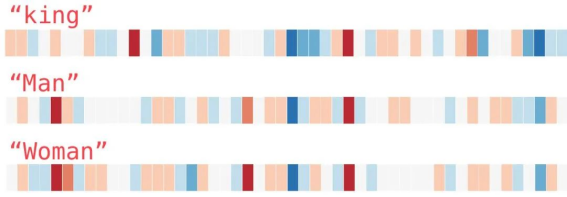
5、看看“Man”和“Woman”彼此之间是如何比它们任一一个单词与“King”相比更相似的?这暗示你一些事情。这些向量图示很好的展现了这些单词的信息/含义/关联。
6、这是另一个示例列表(通过垂直扫描列来查找具有相似颜色的列):
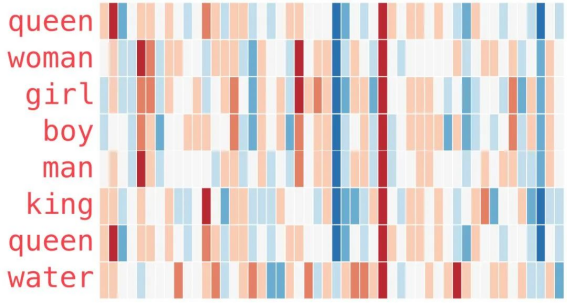
有几个要点需要指出:
1.所有这些不同的单词都有一条直的红色列。它们在这个维度上是相似的(虽然我们不知道每个维度是什么)
2.你可以看到“woman”和“girl”在很多地方是相似的,“man”和“boy”也是一样
3.“boy”和“girl”也有彼此相似的地方,但这些地方却与“woman”或“man”不同。这些是否可以总结出一个模糊的“youth”概念?可能吧。
4.除了最后一个单词,所有单词都是代表人。我添加了一个对象“water”来显示类别之间的差异。你可以看到蓝色列一直向下并在 “water”的词嵌入之前停下了。
5.“king”和“queen”彼此之间相似,但它们与其它单词都不同。这些是否可以总结出一个模糊的“royalty”概念?
以上内容来源:
https://mp.weixin.qq.com/s?__biz=MzU0MDQ1NjAzNg==&mid=2247511995&idx=3&sn=303fcab878857a60bdba6c99aae2d60e&chksm=fb3a0ab0cc4d83a673b909035cd0534f97101303e02f744bb776890f3af8d8472b953e4b56ea&scene=27
通过上面可视化分析,embedding技术将非结构化的数据表达成向量数据,并保留事物之间的关联性等特征。
![]()
03
—
有哪些应用场景
![]() 常见的应用
常见的应用
嵌入(embedding)在文本分类和推荐系统中的应用非常常见。嵌入技术可以将文本数据转化为连续的向量表示,从而使计算机能够更好地理解和处理文本数据。在文本分类任务中,嵌入可以用来提取文本的特征表示。通过将单词或句子转化为嵌入向量,可以将文本表示为固定长度的向量,然后可以将这些向量输入到分类模型中进行训练和预测。嵌入向量能够捕捉到单词或句子之间的语义相似性,从而提高文本分类的准确性和效果。在推荐系统中,嵌入也可以用来表示物品或用户的特征。通过将商品或用户转化为嵌入向量,可以计算出它们之间的相似度,然后根据相似度进行商品推荐或用户个性化推荐。嵌入向量可以将物品或用户的特征表示为连续的向量,使得推荐系统能够更好地理解和匹配不同的物品或用户。![]() embedding 在AIGC中的应用
embedding 在AIGC中的应用
在AIGC的使用中有2个问题困扰着用户
1、AIGC的训练内容是历史数据,最新数据不包含,如果用户想输入新的内容给AIGC存在隐私风险
2、AIGC对于输入长文本例如PDF内容有困难
基于以上两点,使用embedding技术可以解决这两项问题。
1、使用内容向量化存储在向量数据库,输入给AIGC为向量数据,从而避免了隐私风险。
2、通过向量化,将内容切片存储到向量数据库中,当需要使用的时候,AIGC从向量数据库搜索使用。
具体步骤如下:
1.文档切分
2.建立子文档embedding与索引表
3.将LLM任务与子文档embedding做相似度匹配
4.基于LLM产出最终结果
【书籍问答任务】
假设我们有一本讲述人类历史的书籍,我们希望从中提取关于某个重要历史人物的信息,但不想阅读整个文件。为了实现这个任务,我们可以使用嵌入(embedding)和语言模型(LLM)来进行文档构建和内容匹配。
在文档构建阶段,我们可以将PDF文件的文本内容切分成若干子块。然后,使用嵌入模型将每个子文本块转换为向量数组,每个向量表示一个子文本块的语义信息。这些向量数组可以被存储在向量数据库中,并与原始文本块建立索引,以便后续的内容匹配阶段使用。
在内容匹配阶段,当我们需要回答关于该PDF文件的问题时,我们首先使用嵌入模型将问题转换为向量数组。然后,使用相似性度量函数(如余弦相似度)将问题向量与PDF文件的向量进行比较,找到语义上最相关的若干个文本块。接下来,将找到的最相关文本块与问题一起输入到LLM(如GPT-3)中,以得到准确的回答。
通过将嵌入和LLM结合,我们可以实现特定的长文本任务。当前一些类似chatPDF和文档问答产品都采用了类似的技术流程。
出自:https://mp.weixin.qq.com/s/ig6PTf9o7dHagWJ9rphj0A
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Verbatik是一款由人工智能驱动的文本到语音生成器,提供了一个不断增长的库,包含142种语言和口音的600多种自然声音。