王小川发布开源大模型Baichuan2,称中英文全面超越美国Llama 2
发布时间:2024年06月06日

9月6日下午,人工智能(AI)大模型公司 百川智能在北京发布最新70亿、130亿参数的两款Baichuan2系列开源大模型Baichuan2-7B、Baichuan2-13B,文科理科能力全面提升,支持中、英等数十种语言,应用于学术研究、互联网、金融等领域。
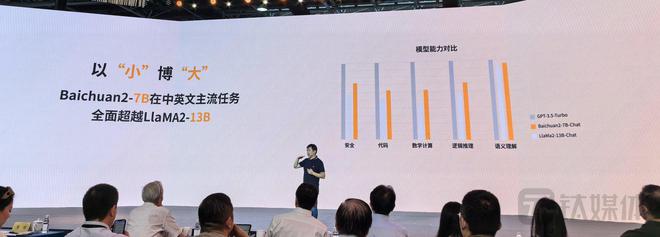
相比一代,Baichuan2数学能力提升49%,代码能力提升46%,安全能力提升37%,逻辑能力提升25%,语义理解能力提升15%,均处于开源模型最好水平。
地址如下:https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/
百川智能创始人兼CEO 王小川表示,70亿参数的Baichuan2-7B在中英文主流任务全面超越Meta研发的开源大模型Llama2-13B。随着国内Baichuan2开源大模型的发布,再用Llama 2作为大家一个开源模型的时代已经过去了。
“我们现在可以获得一个比Llama2更加友好、能力更强的这样一个开源模型,能够去帮助我们扶持中国整个大模型生态发展。那么除了开源模型之外,下次我们再闭源里面可能会有一个新的突破,希望能够在大模型领域为中国社会经济发展带来我们的贡献。”王小川表示。
清华大学计算机系教授、中国科学院院士张钹表示,尽管中国已经发布了众多参数规模从几十亿到几百亿的大型模型和相应的企业,但这些模型大多应用于工业领域,学术研究的应用却相对较少,尤其大模型幻觉问题严重。百川开源大模型在学术研究上的应用显得尤为重要和紧迫,这有助于我们更深入地解释和理解大模型技术。
“我们必须深入探讨和明确这些(可解释、幻觉)问题,只有这样,我们才能更好地发展中国的大模型产品。”张钹称。
据悉,百川智能创立于今年4月10日,由搜狗创始人王小川、前搜狗COO茹立云联合成立,旨在打造中国版的OpenAI,构建中国最好的大模型底座,并在教育、医疗等领域应用落地。截至目前,百川智能已公布首轮5000万美元融资。
过去149天,百川智能平均每28天发布一款大模型,已连续推出70亿、130亿参数的两款开源大模型Baichuan-7B、Baichuan-13B,以及今年8月公布的530亿参数、面向B端用户的闭源通用大模型Baichuan-53B,在写作、文本创作等领域能力已达到行业较好水平。
王小川此前对钛媒体App表示,开源大模型里面,百川智能在中文领域现在就可以替代,在某些应用中已经超越闭源的GPT模型,未来其开源模型能力一定会超越Meta Llama 2。他强调,未来可能80%的场景会用到开源模型。而百川智能目前已完成了“开源+闭源”大模型并行布局,希望做到中国最好的、对标GPT的模型。
据悉,截至目前,百川开源大模型已经在开源社区总下载量超越500万。其中,Hugging Face首周下载量达百万,近一个月的下载量337万。而且在Github上,baichuan系列模型是星标月涨幅最快的中国大模型。
企业端,截至目前,已经又超过200家企业已申请百川大模型开源和商业授权,并已将百川模型投入实际生产场景。企业涵盖互联网、软件和信息技术、金融、法律、教育、制造业、企业服务等众多领域,客户包括阿里云、腾讯、火山引擎、京东科技、顺丰科技、浪潮、中国农业银行、蔚来汽车等。
今年8月31日,百川智能旗下产品“百川大模型”等10余款大模型产品完成备案,成为中国首批面向公众提供类似ChatGPT服务的 AI 大模型产品。
此次,百川智能公布的最新开源大模型Baichuan2系列,文科理科全面提升,拥有2.6TB训练的超大规模语料,数据方面规模大、覆盖全、质量优,篇章、段落、句子质量打分,支持细颗粒采样,训练则是高效、稳定、可预测,安全方面实施了安全价值观对齐,实现了多阶段多目标的强化学习。同时,百川Baichuan2系列开源大模型提供更透明、更开放,公布了3000亿-2.6万亿tokens的模型训练中间过程,助力大模型研究。
另外,王小川还宣布,中国计算机学会(CCF)和百川联合成立大模型研究基金,旨在推动围绕大模型不同阶段、不同维度等相关技术研究,支持医疗、开放世界Agent。而且,百川智能还将与亚马逊云科技成立AI黑客松活动,在医疗健康、游戏娱乐两大赛道支持AI大模型研究,冠军奖励超过20万元。
合作伙伴方面,百川智能与阿里云、高通、英博数科、瀚博半导体、火山引擎、寒武纪、华为等公司合作落地百川大模型。
王小川早前向钛媒体App透露,百川智能将在今年第四季度发布千亿参数模型,预计明年一季度前后推出 “超级应用”。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
Codeium是一款智能的代码生成工具,它可以根据用户的描述自动生成网站的代码。