花7000块实测Claude2.1 – 200K Token的超大杯效果究竟怎么样?
发布时间:2024年06月06日
昨天Claude2.1正式发布了,更新了一系列的新能力,不过只对API用户开放。

大概总结一下,200K Tokens的上下文窗口、模型幻觉率的显着降低、系统提示以及他们的新测试功能:工具使用。
其他的没啥可说的,重点聊聊这个200K Tokens的上下文。
记得几个月之前,Claude率先推出100K Token,引起了不小的风波,毕竟在那个上下文都还只有4K Tokens的年代,100K Token可是扎扎实实的降维打击。
而这次,Claude2.1号称全球第一,扔出了2倍容量的200K Token。大家可能对Token没啥概念。我换种描述来说。
200K Token等于470页的PDF材料。
按Claude自己的话说,你可以扔你整个代码库和技术文档、扔一整个财务报表,甚至把《奥德赛》或者《伊利亚特》扔进去。
这下是不是就大概有点数了?以前4K的小窗口,扔个几页PDF都费劲,现在,随便扔。
但是支持这么大的容量以后,使用起来到底怎么样?你不能光加容量,但是质量不加吧,就好比你喝瑞幸,以前是个普通中杯,给你放了半杯的冰,现在他说升级了,给你来了一口缸,但是缸里依然还特么的全是冰,咖啡就那么几口,那这升级有蛋用,对吧。
Token也是一样的道理,你说是升级了200K,但你实际到50K就全都忘干净了,那你100K和200K有啥区别?
所以X上一个大佬Greg Kamradt,为了弄明白Claude2.1的200K Token,究竟实测效果怎么样,就调用Claude 的API做了个压力测试。
他做个压力测试,花了1016 美金。。。。
你没看错,1016美金,折合人民币一共7255元。。。
只能说,太特么壕了,壕特么上天了。。。
直接放他的测试结果图,为了大家阅读体验良好,我给做成中文版的了(图片可能在公众号上有压缩看不清,看完文章后可以对着我公众号私信"测试图",我自动发你高清的原图)。
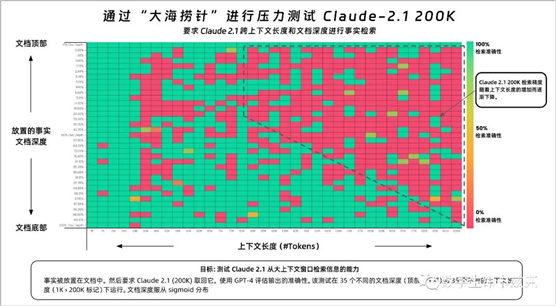
这个测试Greg Kamradt将其命名为"大海捞针"压力测试。
测试的目的是评估Claude从大量文本中检索信息的能力,特别是当信息被放置在文档的不同位置时的准确率。
横轴表示上下文长度(以Token表示),纵轴表示文档深度的百分比,这表示事实被放置在文档的位置。横轴应该比较好理解,就是给的信息总量Tokens数,从1K到200K不等。
纵轴我稍微解释一下,"文档深度百分比"实际上是表示要信息(事实)被放置在整个文档中的位置,就是你要从大海里捞的那根针所处的位置。你可以想象一篇文章,它从头到尾都有文字。如果我们把这篇文章比作一堆纸叠在一起,那么“文档深度”的百分比就像是你从最顶部的纸张向下数,直到你找到那条信息所在的地方。如果信息在文档的最开始部分,那么它的文档深度接近0%。如果信息在文档的正中间,那么它的文档深度接近50%。如果信息在文档的最末尾,那么它的文档深度接近100%。如果一篇文章有100行,一个重要的事实被放在了第50行,我们可以说这个事实的文档深度是50%。如果这个事实在第25行,那么深度是25%;如果在第75行,深度就是75%。这个百分比告诉我们事实在文章中的位置,而不管文章有多长。大概就是这个意思。可以看到,整个测试,Claude红了半边天,一半都检索失败,根本找不到。甚至可以看到文档到了200K的时候,除非你把那根"针"放在最顶部或者最底部,也就是文档深度0%的位置,才能成功。
甚至你放在1%的文档深度的位置都能失败,简直就离谱。发现:
- 在20万个令牌(近470页)的文档深度下,Claude 2.1能够回忆起某些事实
- 位于文档最顶部和最底部的事实被几乎100%准确地回忆起来
- 位于文档顶部的事实的回忆表现不如底部(与GPT-4类似)
- 从大约90K个令牌开始,文档底部的回忆表现开始逐渐变差
- 在较低的上下文长度下,并不保证有良好的表现
结论以及如何做:
- 提示工程很重要。值得对您的提示进行调整,并进行A/B测试以测量检索的准确性
- 不能保证您的事实一定会被检索到。
- 更少的上下文 = 更高的准确性 - 这是众所周知的,但是如果可能的话,减少您发送给模型的上下文量可以增加它的回忆能力
- 位置很重要。但是放在文档最开始和文档深度50%到100%区间的事实似乎能被更好地回忆起来。
- 提示工程很重要 - 值得对您的提示进行调整,并进行A/B测试以测量检索的准确性
可以看到,Claude2.1的这个200K表现并不尽人意,更不能对它抱有过高的信任。总量达100K之后,检索成功率甚至只有50%不到。
前几天GPT4也发布了128K的版本,虽然它比Claude2.1少了近一半,但依然是个容量极大的超大杯了。我们再看看Greg Kamradt之前做的GPT4 128K的评测,来跟Claude2.1做一个横向的对比。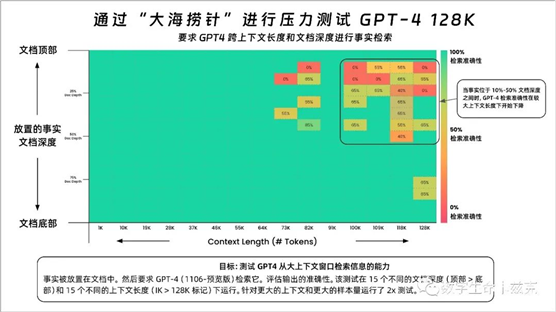 绿油油一片。
绿油油一片。
整个检索成功率几乎都保持着成功,只有到了73K以后,在7%~50%的文档深度之间,成功率才有所降低。可以从这个压力测试看出来,GPT4保持着遥遥领先的姿态,甩了Claude一大截。Token这个东西,容量越大当然越好,但是相应的,质量你得跟上吧。光大容量,结果掀开一看,全是冰块,那还玩个屁。
OpenAI的一出闹剧,依然改变不了GPT4在AI行业的王者地位。
希望后来者,能真正的给OpenAI一些压力。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一款由 AI 驱动的建筑住宅设计软件,能让建筑师、建筑商和开发人员能够立即快速生成数千个建筑住宅设计方案。