重磅:Google发布最大最强多模态大模型“Gemini”,称其性能超越GPT-4,新一轮“军备”竞赛开启
发布时间:2024年06月06日

来自Google最新官方博客消息,Google终于对外发布了自己的多模态大模 Gemini 1.0,这是google迄今为止最强大、最通用的人工智能模型。
Gemini 天生多模态,这意味着它可以理解、操作和结合不同类型的信息,包括文本、代码、音频、图像和视频。
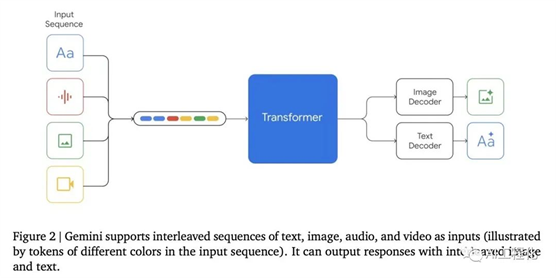
它还非常灵活,能够高效地运行在从数据中心到移动设备上的各种环境中。Gemini 的第一个版本,Gemini 1.0,针对三种不同的大小进行了优化:Gemini Ultra 用于高度复杂的任务,Gemini Pro 适用于广泛的任务,Gemini Nano 用于设备上的任务。
业界一流的模型性能
Gemini
Ultra 在
32 个广泛使用的学术基准测试中的 30 个上超越了当前的最新成果,这些基准测试用于大型语言模型的研究和开发。它是第一个在 MMLU(大规模多任务语言理解)上超越人类专家的模型,MMLU 测试了世界知识和在 57 个科目(如数学、物理、历史、法律、医学和伦理)中的解决问题能力。
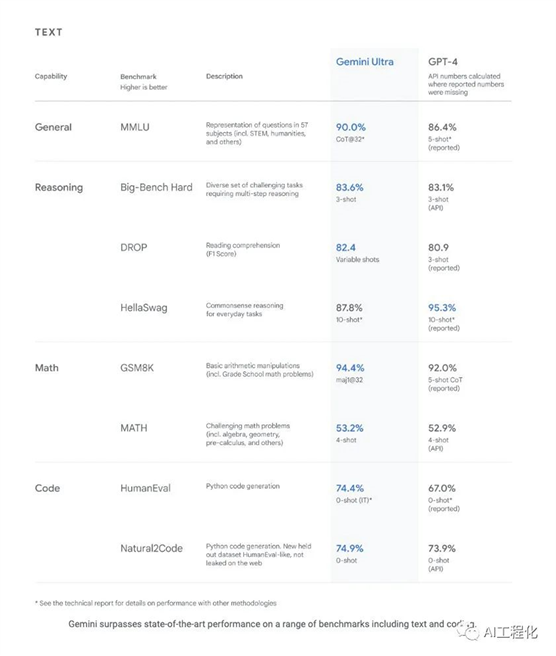 Gemini Ultra还在新的MMMU基准上获得了59.4%的最新得分,该基准包括跨越不同领域的多模式任务,且需要推理。通过我们测试的图像基准,Gemini Ultra的表现超过了以前最先进的模型,而没有从图像中提取文本以进行进一步处理的对象字符识别(OCR)系统的帮助。这些基准突出了双子座的本土多模式性,并表明了Gemini有更复杂推理能力的早期迹象。
Gemini Ultra还在新的MMMU基准上获得了59.4%的最新得分,该基准包括跨越不同领域的多模式任务,且需要推理。通过我们测试的图像基准,Gemini Ultra的表现超过了以前最先进的模型,而没有从图像中提取文本以进行进一步处理的对象字符识别(OCR)系统的帮助。这些基准突出了双子座的本土多模式性,并表明了Gemini有更复杂推理能力的早期迹象。
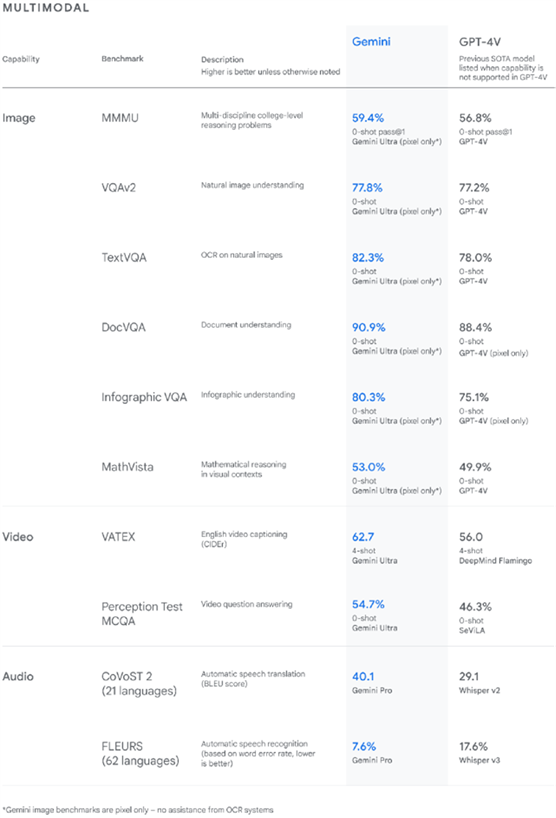
领先一代的技术能力
过去多模态的实现方式通常是经过模态转换和拼接,虽然能够完成一些任务,如描述图像,但在概念性更强、更复杂的推理方面却很吃力。而Gemini设计为原生多模态模型,从一开始就在不同模态上进行预训练,然后,我们利用额外的多模态数据对其进行微调,以进一步提高其有效性。这有助于 Gemini 从一开始就能无缝地理解和推理各种输入,远远优于现有的多模态模型,而且它的功能几乎在每个领域都是最先进的。Gemini 1.0 具有复杂的多模态推理能力,可帮助理解复杂的书面和视觉信息。这使它在发掘海量数据中难以辨别的知识方面具有独特的技能。通过阅读、过滤和理解信息,Gemini 1.0 能够从成千上万的文档中提取独到的见解,这将有助于在从科学到金融等众多领域以数字化的速度实现新的突破。
Gemini 1.0 被训练用于同时识别和理解文本、图像、音频等,使其在解释数学和物理等复杂科目的推理方面表现出色。
它还可以理解、解释和生成流行编程语言(如 Python、Java、C++ 和 Go)中的高质量代码。Gemini Ultra 在多个编码基准测试中表现出色,包括 HumanEval(评估编码任务性能的重要行业标准)和 Natural2Code(我们内部保留的数据集,该数据集使用作者生成的源代码而非基于网络的信息)。
更可靠、更可扩展、更高效
Google 使用其针对 AI 优化的基础设施和自家设计的 Tensor Processing Units (TPUs) v4 和 v5e 来训练 Gemini 1.0。公司还宣布了迄今为止最强大、最高效、最可扩展的 TPU 系统——Cloud TPU v5p,专为训练尖端 AI 模型而设计。

让Gemini走向世界
Gemini 1.0 现在正在逐步应用于各种产品和平台。它将用于 Google 的产品,如 Bard 和
Pixel,开发者和企业客户可以从 12 月 13 日起通过 Google AI Studio 或 Google Cloud Vertex AI 中的 Gemini API 访问 Gemini Pro。安卓开发者也将能够通过 AICore,在安卓 14 上使用
Gemini Nano 开发,该功能将从 Pixel 8 Pro 设备开始提供。
来自:https://blog.google/technology/ai/google-gemini-ai
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
MealPractice是一款用户友好的自定义食谱生成器,使用户能够毫不费力地创建自定义食谱。