自己电脑上跑大语言模型(LLM)要多少内存?
发布时间:2024年07月12日
在本地电脑上运行大型语言模型(LLM),需要考虑的关键因素之一就是电脑的内存够不够。希望能通过这篇文章让各位有能力简单判断自己的电脑大概能跑什么样的模型。
1. 怎么看模型名字?
模型名字一般由两部分构成,[模型名称] + [参数量]。比如Gemma 7B里,Gemma是模型的名称,一般指代一个系列的模型。7B代表这个模型文件大约有7 billion / 70亿个参数,一般参数量越高的模型能力越强。
2. 模型精度
除了模型参数量,影响模型大小的另一个比较重要的指标是[精度](precision),一般看到的full precision指的是32bit,half precision指的是16bit,常见的还有8bit,4bit等。这个指标一般能在模型说明里找到。
3. 模型文件大小
模型文件大小可以通过看[参数量]+[精度]来简单计算。全精度/Full precision下,一个参数/parameter通过4byte来存储。1B(10亿)个参数通过4GB来存储,总结如下表:
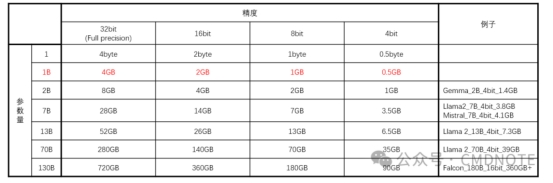
可以看到的是:
·
一般模型文件的实际尺寸要比简单计算的尺寸大
·
·
即使是同样参数和精度的模型,实际尺寸也不一样
·
·
降低模型精度的过程叫量化(Quantization),不同模型对降低精度的敏感程度不一样,比如在这项(https://huggingface.co/blog/falcon-180b)测试中,研究人员发现Falcon 180B低精度版本在表现上变化不大。
·
4. 我到底要多少内存才够?
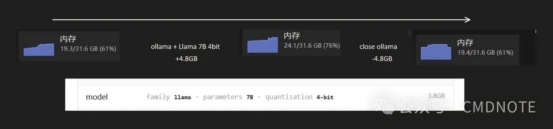
以我用ollama + Lllama 7B 4bit 做推断(Inference,问大模型问题)为例,模型文件大小是3.8G,实际运行的时候电脑内存会多占用大概4.8G左右。
5. 如果我要训练模型呢?
上文表格里的模型大小和我例子里的内存使用情况都是仅考虑使用场景是模型推断,既一般的问答。如果要训练模型的话,以使用的训练模式不同,优化方式不同,所需要的计算资源会更多。
6. 内存?显存?硬盘?
具体用的什么取决于你用什么方案来跑大模型的,比如ollama在Windows上主要消耗电脑内存,但是推断的时候也会介入GPU计算。我之前测试GPT4ALL的时候他是用的内存。NVIDIA GTX GPT主要用的就是显存。有一些解决方案甚至是用的硬盘空间,不过设置对普通用户来说不那么直接,而且软硬件优化也是另一个需要考虑的因素。一般建议看一下自己使用的是哪一种方式,然后官方的推荐配置是什么。
7. 那我应该怎么选?
具体用哪家的模型可以看各方的评测,有一些模型适合特殊的场景。但是用多大的模型,我见过有专家推荐:跑你能跑的最大的4bit的模型。我感觉这个建议足够普通用户使用了。具体用多大参数的模型,各位可以根据上面的表格来粗略估算一下,比如要跑4bit的Llama2 13B,模型文件就7.3G,8G内存就不太够了,16G内存也要看看是不是运行其他软件的时候够。
出自:https://mp.weixin.qq.com/s/5C9RlA5Yi8avfgVFCJtm4Q
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一个专为网站设计的人工智能聊天机器人,旨在通过个性化的对话方式提供更好的用户体验,即时回答访问者的问题。它通过对网站内容进行训练,能够回答与网站内容相关的任何问题,从而帮助用户创建和训练自己的AI聊天机器人。