硬核Prompt赏析:HuggingGPT告诉你Prompt可以有多“工程”
发布时间:2024年06月06日
论文下载: 2303.17580.pdf
2303.17580.pdf
HuggingGPT是近期非常火热的Agents方向的一个代表,它让ChatGPT这样的LLM能够使用HuggingFace社区的各种模型(包括但不仅限于文生图、图生文、语音转文字、文字合成语音等),从而让LLM能驱动其他智能Agent,实现多模态能力。
论文原文和中文介绍如下:
- 论文原文
- HuggingGPT:https://arxiv.org/abs/2303.17580
- 中文介绍
- HuggingGPT介绍
其工作原理如下图:
LLM作为控制器(Controller),用来理解用户需求,然后结合HuggingFace社区的模型,将用户任务分解为任务规划(Task Planning)、模型选取(Model Selection)、任务执行(Task Execution)和响应生成(Response Generation)等四个步骤。这是一个比较复杂的工作流,一个典型的任务执行过程如下:
在阅读原文的过程中,我发现HuggingGPT的Prompt设计也是相当“硬核”的:虽然是自然语言的表达,但是其间充满精巧的工程设计心思。下面就来解析一下整个过程中充满匠心的Prompt。
步骤1:任务规划(Task Planning)
该阶段,ChatGPT分析用户请求,理解其意图,将其分解成能被解决的子任务。那么,它的Prompt是什么样的呢?
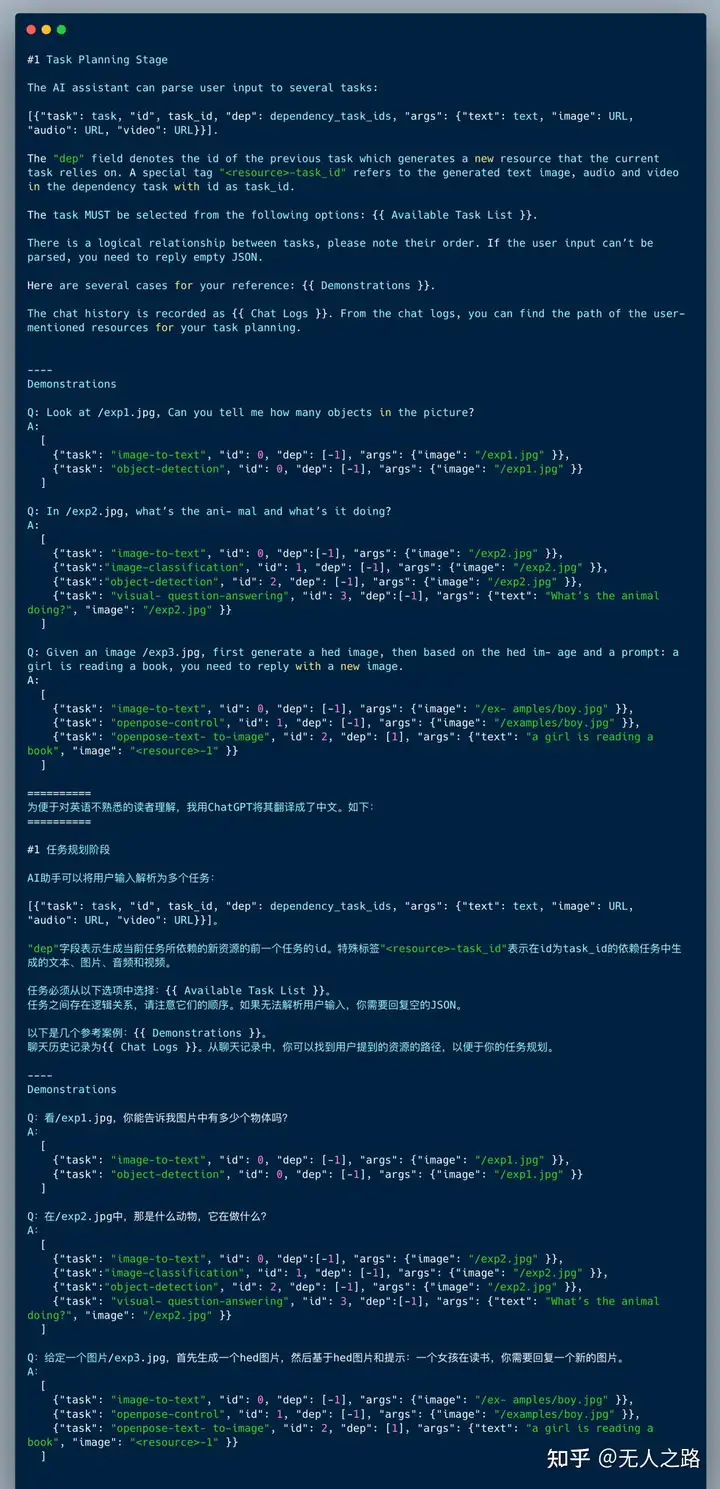
在上面的Prompt设计中,HuggingGPT综合使用了“基于规范的指令”(specification-based instruction)和 “基于示范的解析”(demonstration-based parsing)的方法。
“基于规范的指令”是指对Task做了规范约束,必须是下面的这种格式,包含任务内容(task)、任务id(id)、任务依赖(dep)和参数(args)等四个要素:
[{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]
这种设计从浅层次上讲,是对任务分解过程输出的格式要求;从深层上讲,是对模型调度的系统设计,饱含对整个系统如何工作的深刻理解。特别是这里的dep和args,从程序员的角度看,已经是典型的系统接口设计。
大模型在训练过程中,经历过指令微调和基于人类反馈的强化学习, 已经具备一定的指令遵从能力。为了让它进一步了解要怎么做,Prompt中给它提供了若干“示例”(Demonstrations)。这会激发大模型的基于上下文学习(In-Context Learning)或者叫做Few-shot learning能力,从而产生更好的理解和生成。这就是文章中提到的demonstration-based parsing。
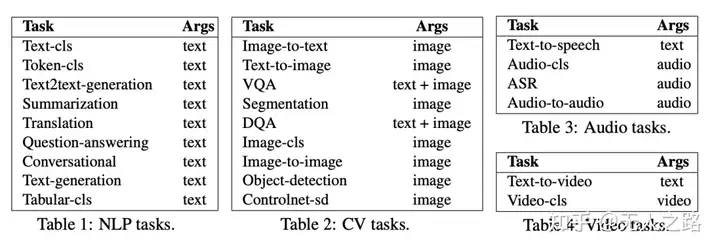
除此之外,Prompt还会给LLM提供Available Task List和Chat Logs,给大模型提供可用的HuggingFace模型列表和对话历史,提供更多、更准确的上下文信息。其中的Available Task List应该就是下面这些,包括自然语言处理、计算机视觉、语音和视频相关的不同类型的任务:
步骤2:模型选择(Model Selection)
为了运行步骤1中规划好的子任务,ChatGPT需要从托管在HuggingFace上的模型中选取合适的模型来执行。这个阶段的Prompt如下:
这个阶段的Prompt比较直白,不过也跟第一阶段的Prompt一样,给LLM提供了比较明确的“备选模型”(Candidate Models)的信息。不过这个“备选模型”数据,不是一个静态不变的,而是有比较精细的加工,其获取过程包括:
- 模型描述获取。需要从HuggingFace网站获取每个模型的功能、架构、领域、许可等各种信息,作为喂给LLM做模型筛选的输入。
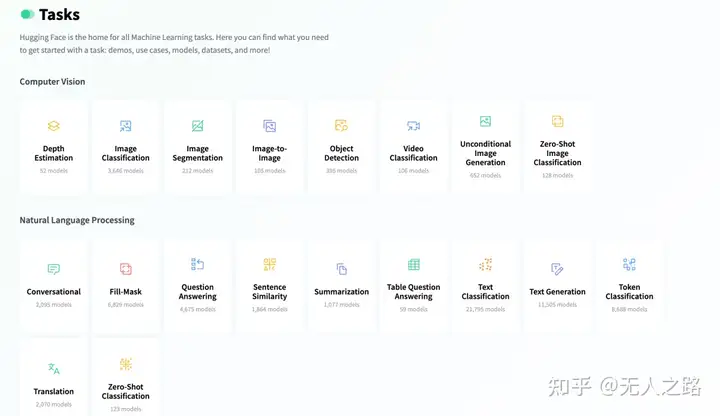
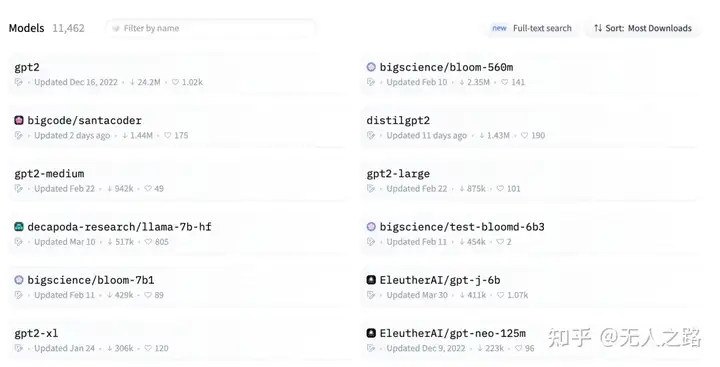
- 模型初筛。由于Prompt有长度限制,不能在里面塞入HuggingFace社区上的所有模型描述,因此要对模型进行初筛。初筛的第一个条件是任务类型,根据步骤1的结果,得到task字段就是任务类别,比如“image-to-text”。用这个任务类别,和模型描述中的功能或者分类做匹配即可,得到该任务类型下的所有模型描述。下图就是HuggingFace官网上不同Task对应的模型数。
- 模型细筛。按照任务初筛之后,模型还是会有很多。比如文本生成类的模型,有10000+个,gpt-3.5-turbo的token限制是4096,显然不能包含这个类别的所有模型描述。于是还要进行进一步的细筛。文章中提到是根据模型的下载量取TopN来实现,下载量很大程度上反应了该模型的质量和受欢迎程度,可以作为进一步筛选的标准。
细筛之后的模型描述,就能放在一个Prompt,提供给大模型做基于上下文的学习,进而选出合适的模型。
从上面的过程可以看出,这非常能体现出Prompt Engineering的Engineering部分,要得到最终执行的Prompt,会考量比较多的限制条件,通过编程来动态生成Prompt。
步骤3:任务执行(Task Execution)
任务执行就是唤起选中的模型,执行算法,最后返回结果给到ChatGPT。这个过程不是由LLM执行的,从而不需要Prompt设计。
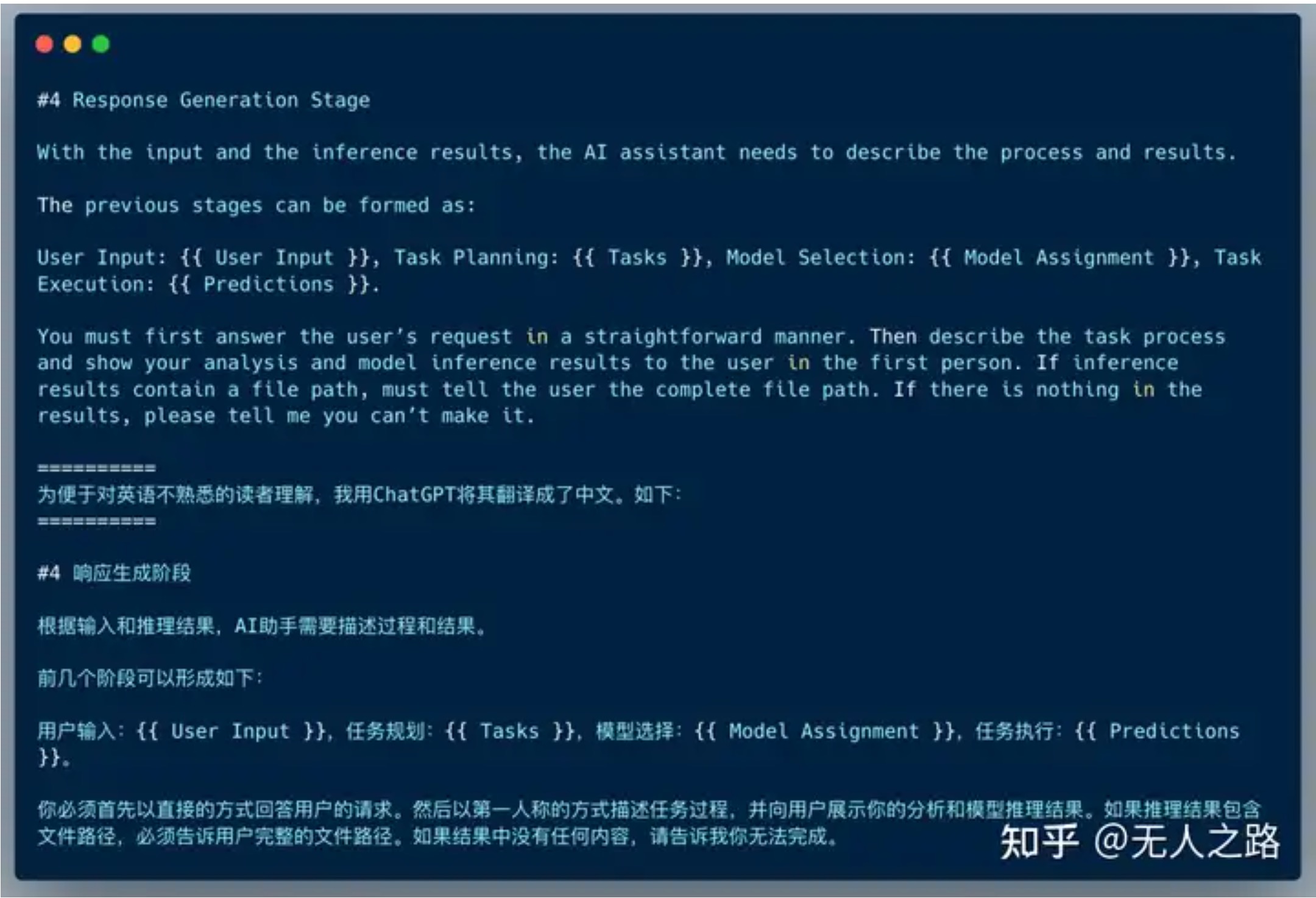
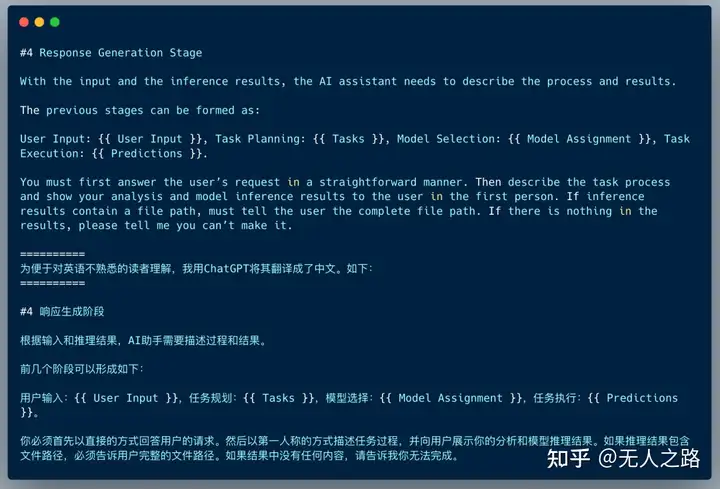
步骤4:响应生成(Response Generation)
最后,ChatGPT汇集各个模型的运行结果,给用户生成一个答案。这个过程的Prompt是:
再来欣赏一个例子(更多示例见论文原文):
小结
整个HuggingGPT非常“硬核”的Prompt设计,我觉得非常好地阐释了“提示词工程”(Prompt Engineering)中的“工程性”。它包括下面几个方面:
- Prompt流设计。HuggingGPT不是一个单一的任务节点,而是一个工作流,分成了4个步骤。因此它也不是一个Prompt就能搞定的,需要设计多个Prompt,来承载整个工作流。除了每一步要设计好自己的Prompt之外,还要在Prompt上做好不同任务节点的衔接。
- Prompt动态生成。在步骤2“模型选择(Model Selection)”中,Prompt是动态生成的,其中的“备选模型”部分是通过模型描述获取、模型初筛、模型细筛等一系列过程得到的。这个过程会涉及到系统设计、编程实现等软件工程的实施。这跟传统软件开发中,动态生成用于查询和修改数据的SQL语句非常像,会有一个庞大但精巧的工程来实现它。
- Prompt静态技巧。在任务1“任务规划(Task Planning)”中,Prompt是静态的,这里综合使用了“基于规范的指令”(specification-based instruction)、 “基于示范的解析”(demonstration-based parsing)等常用的Prompt技巧。每一个动态的Prompt在给到LLM的时候,也可以看做是静态的Prompt,因此如何让Prompt更具表达力,就可以综合用到我们前面文章中提到的各种技巧。
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
一个人工智能艺术生成器,由先进算法和模型驱动的AI平台,可让您将文字转换为独特的图像和视频。创建、下载和分享您的创意设计。