重磅来袭!Llama中文社区开源预训练中文版Atom-7B大模型
发布时间:2024年06月06日
完全开源可商用!Llama中文社区联合AtomEcho(原子回声)重磅发布基于Llama2的中文预训练大模型:原子大模型
Atom-7B
| Atom-7B
介绍
目标泛智能体大模型
不同原子有不同的特性,原子大模型也可以进化出不同的能力,一些专注于自然语言处理,一些负责图像识别,一些负责语音识别,还有一些可能是专为解决特定类型的科学问题而设计。原子大模型未来可以不断地进化迭代出不同能力,并且进行组合,类似于“化学键”,生成更为复杂的智能体Agent,解决更为复杂的问题。
| 中文优化
从中文预训练开始,持续迭代升级
🎯中文数据
通过测试我们发现,Meta原始的Llama2 Chat模型对于中文问答的对齐效果欠佳,大部分情况下都不能给出中文回答,或者是中英文混杂的形式。因此,基于中文数据对Llama2模型进行预训练和微调十分必要。
Atom-7B在Llama2-7B的基础上,采用以下中文数据进行持续预训练:
|
类型 |
描述 |
|
网络数据 |
互联网上公开的网络数据,挑选出去重后的高质量中文数据,涉及到百科、书籍、博客、新闻、公告、小说等高质量长文本数据 |
|
Wikipedia |
中文Wikipedia的数据 |
|
悟道 |
中文悟道开源的200G数据 |
|
Clue |
Clue开放的中文预训练数据,进行清洗后的高质量中文长文本数据 |
|
竞赛数据集 |
近年来中文自然语言处理多任务竞赛数据集,约150个 |
|
MNBVC |
MNBVC 中清洗出来的部分数据集 |
📚深度优化的高效中文词表
为了提高中文文本处理的效率,我们针对Llama2模型的词表进行了深度优化。首先,我们基于数百G的中文文本,在该模型词表的基础上扩展词库至65,000个单词。经过测试,我们的改进使得中文编码/解码速度提高了约350%。此外,我们还扩大了中文字符集的覆盖范围,包括所有emoji符号😊。这使得生成带有表情符号的文章更加高效。
对于Llama2原生词表中的一些特殊情况,如数字、英文等,我们尽可能地避免对其进行修改或替换。这样做的目的是为了最大限度地保留Llama2原有的能力,同时又不影响中文处理的效果,实现一种既能提高中文处理效率又能保持Llama2原有性能的方法。
| 训练过程
⭐支持更长上下文的模型结构
基于当前最优秀的开源模型 Llama2,使用主流Decoder-only
的标准 Transformer 网络结构,支持 4K 的上下文长度(Context Length),为同量级模型中最长,能满足更长的多轮对话、知识问答与摘要生成等需求,模型应用场景更广泛。
⭐采用FlashAttention-2进行高效训练
Atom-7B采用了FlashAttention-2技术高效训练。由于在处理较长的输入序列时,内存消耗的问题可能会导致“内存爆炸”现象。FlashAttention-2是一种高效注意力机制的实现方式之一,相较于传统的注意力技术(Attention),它拥有更快的速度以及更加优化的内存占用率。
⭐基于NTK的自适应上下文扩展技术
§
可在不继续训练模型的情况下支持更长的上下文
§
§
Atom-7B模型默认支持4K上下文,利用NTK技术可扩展至18K+
§
§
经过微调可以支持到32K+
§
| 配置要求
💻推理配置
可以在消费级显卡部署
实际应用中,消费级显卡要比专业显卡便宜的多(比如同样都是24G显存,RTX3090相比A10更具有性价比)。
消费级显卡难以部署FP32的模型参数,可以选择用FP16、INT8和INT4进行部署,部署Atom-7B需要的配置如下:
§
FP16模型参数需要至少14G显存,可在RTX3090上部署
§
§
INT8模型参数需要至少8G显存,可在RTX3080上部署
§
§
INT4模型参数需要至少5G显存,可在RTX3080上部署
§
| 部署方案
训练或者微调之后的模型,如果直接使用原生transformers进行部署速度较慢(如下方案2),可使用方案1进行加速推理:
方案1:FasterTransformer && Triton
对于生产环境的部署,可以使用triton inference server,然后使用fastertransformer-backend。Fastertransformer-backend是一个支持多钟LLM模型的backend,实现了很多高性能的针对transformer的算子。具体使用方式可以参考:
https://github.com/FlagAlpha/Llama2-Chinese/blob/main/inference-speed/GPU/FasterTransformer_example/README.md
方案2:直接使用transformers
直接使用transformers推理,适用于简单的本地测试,快速调试模型的效果。

🚀Gradio快速搭建问答平台
基于gradio搭建的问答界面,实现了流式的输出,将下面代码复制到控制台运行,以下代码以Atom-7B模型为例,不同模型只需修改一下代码里的模型名称就好了😊
·
python examples/chat_gradio.py --model_name_or_path FlagAlpha/Atom-7B
| 样例展示
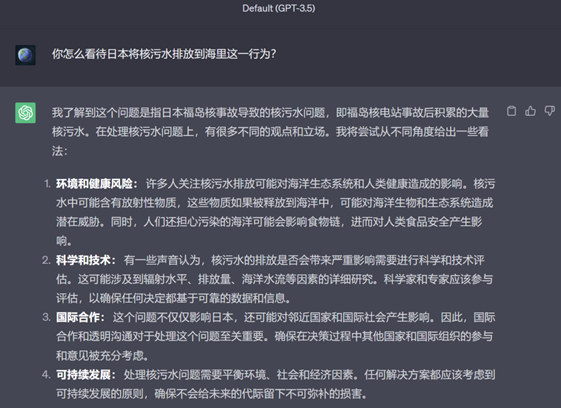
如何看待日本核污水排海?
Atom-7B回答:(更为直接和感性)

GPT-3.5回答:(理性分析和中庸)
| 下载使用
进入Llama中文社区网页:
https://llama.family
下载 Atom-7B 模型
出自:https://mp.weixin.qq.com/s/Bdx0JTVh1kgPn5ydYxIkEw
如果你想要了解关于智能工具类的内容,可以查看 智汇宝库,这是一个提供智能工具的网站。
在这你可以找到各种智能工具的相关信息,了解智能工具的用法以及最新动态。
输入你的论文主题,可以提供一个参考的写作思路