聊天大模型的输出速度应该是多少?单张显卡最多可以支持多少个人同时聊天?来自贾扬清最新的讨论~
发布时间:2024年06月06日
大模型应用中一个非常重要的问题就是大模型的响应速度。尤其是作为聊天应用来说,在用户输入之后,大模型可以在多短的时间内给出回应对于用户体验来说影响巨大。这里有2个问题经常会被大家所关注,一个是大模型每秒输出多少个tokens就可以满足用户的日常聊天使用,另一个问题是单张显卡最多可以支撑多少个用户的聊天需求。在前几天的vllm meetup上,贾扬清给出了一些讨论,他认为我们目前可能高估了大模型的聊天应用成本。
本文来自DataLeanerAI的博客:
https://www.datalearner.com/blog/1051696951947094

适合人类阅读的大模型输出速度
单张显卡可以支撑的同时聊天人数
关于聊天大模型性能的输出基准
适合人类阅读的大模型输出速度
其实大模型的输出速度在不同的场景下要求可能是不一样的。在日常交互的场景中,大模型的输出速度只要满足用户的阅读速度一般就可以。
而成年人的平均阅读速度在每分钟200-300个单词之间,不过不同的人差别很大,下图展示了一些研究结论:
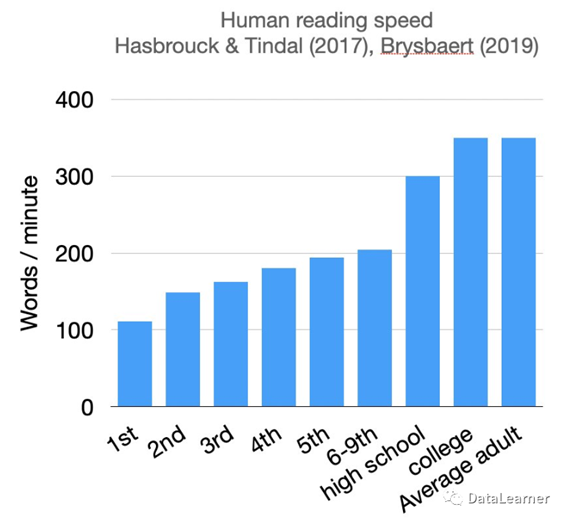
可以看到,根据相关的研究,高中生的阅读速度是每分钟300个单词左右,而成年人在每分钟350个单词左右,约等于每秒5.5个单词左右。这意味着,如果大模型的输出速度在每秒有5-6个单词即可满足日常的阅读。
根据贾扬清的测试,LLaMA2-7B在A10显卡上单次请求下,每秒可以生成40个tokens(约30个单词),完全超出了人类的阅读需求。如果采用并发请求,即使有128个并发,模型每秒依然有10个tokens的输出速度,也是完全满足聊天需求的。
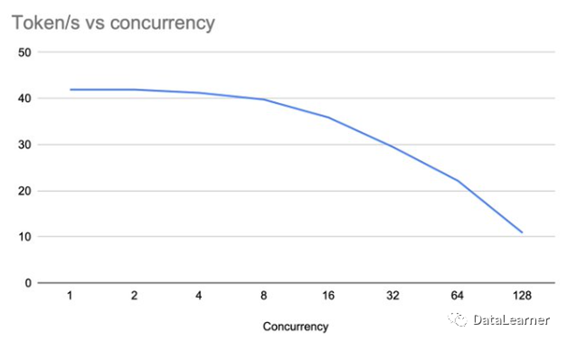
单张显卡可以支撑的同时聊天人数
从上面的讨论可以看到,使用并发技术,一个A10上运行LLaMA2-7B模型,即使有128个并发请求,依然有每秒10个tokens的输出,这意味着可以支持128个人同时聊天也没有问题。
因此,贾扬清认为我们过于估计LLMs的成本,因为有时候我们过于关注单个查询的速度。因此,当考虑大型语言模型的性能时,我们应该看总体吞吐量而不仅仅是单个查询的速度。
以单张A10显卡运行LLaMA2-7B模型为例,贾扬清他们优化后的吞吐量可以达到每秒2500个tokens峰值,这意味着单张显卡可以支撑几百个LLaMA2-7B的并发聊天请求。
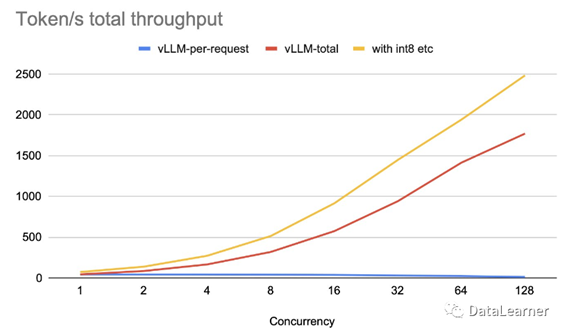
上图展示了贾扬清他们测试的A10运行LLaMA2-7B的吞吐量测试。在128个并发的情况下,基于vLLM-total方式可以达到1700个tokens每秒,而int8量化等优化之后甚至达到了2500个tokens每秒!
关于聊天大模型性能的输出基准
这是贾扬清发表的关于大模型性能的一个简单的讨论,但是十分具有参考价值。不过,实际应用中也不能简单地按照上面的数据来操作。还有一些其它因素需要考虑。
例如,即使是聊天场景,不同的聊天内容大模型的响应速度也是有差别的。复杂的推理可能需要更长的响应时间。而在类似技术支持、科研的场景,很多用户也可以接受更慢的速度。
此外,很多时候,模型会输出大量不必要的废话。例如,使用ChatGPT时,用户通常会快速滚动答案,简要检查是否合理,并只阅读有意义的部分。并不是ChatGPT生成的每一个回应都是供人完全阅读的。因此,确保输出简洁、精确且有用可能比仅仅提高输出速度更重要。
对于某些应用,如实时聊天,延迟可能比吞吐量更重要。但对于批量处理或后台任务,吞吐量可能更为关键。设计和优化模型时需要权衡这两者。
最后,上面的数据是贾扬清基于vLLM做的优化和测试,实际中,不同的方法和模型也会有一些不一样的结论,因此,需要结合自身的情况测试才是最合适的~
出自:https://mp.weixin.qq.com/s/tz5PqTYmnkdMW14f62kFmg
Perplexity AI 是一种新的 AI 搜索引擎,旨在使用大型语言模型为复杂问题提供准确的答案。