ComfyUI官方使用手册【官网直译+关键补充】
发布时间:2024年06月06日
官方网址:ComfyUI
Community Manual (blenderneko.github.io)
作者提示:
1.官方网址上的内容没有全面完善,我根据自己的学习情况,后续会加一些很有价值的内容,如果有时间随时保持更新。
2.官方网址是英文而且阅读很不方便,你打开看就知道了,我也是为了自己学习才自己重新编辑并翻译了一遍,翻译使用GPT-4,并且自己根据理解,有一定修改,以更符合中文的阅读习惯!
以下开始是翻译内容:
一、开始入门
欢迎来到ComfyUI社区文档!这是与ComfyUI相关的文档的社区维护存储库,ComfyUI是一个强大且模块化稳定的gui和后端。本页面的目的是让您开始使用ComfyUI,运行您的第一个生成,并提供下一步探索的一些建议。
(一)安装
我们这里不会详细介绍ComfyUI的安装,因为该项目正在积极开发中,这往往会改变安装说明。相反,请参阅GitHub上的自述文件,并找到与您的安装(Linux、macOS或Windows)相关的部分。GitHub网址如下:
(二)下载模型
如果您完全不了解任何与Stable Diffusion相关的事物,您首先要做的就是获取一个您将用于生成图像的模型检查点。
经验丰富的用户: 如果您已经有文件(模型检查点、嵌入等),则不需要重新下载这些文件。您可以将它们保留在相同的位置,只需告诉ComfyUI在哪里可以找到它们。为此,请找到名为extra_model_paths.yaml.example的文件,将其重命名为extra_model_paths.yaml,然后编辑相关行并重新启动Comfy。完成后,跳到下一节。
您可以在Civitai或HuggingFace等网站上找到各种各样的模型。首先,获取您喜欢的模型检查点并将其放在models/checkpoints(如果不存在则创建该目录)中,然后重新启动ComfyUI。
(三)Comfy的第一步
在这一阶段,ComfyUI应在浏览器选项卡中启动并运行。加载的默认流程是一个很好的起点来熟悉它。要导航画布,您可以拖动画布或按住空格键并移动鼠标。您可以通过滚动来缩放。
意外会发生: 如果您弄乱了某些东西,只需在菜单中点击“加载默认”即可将其重置为初始状态。
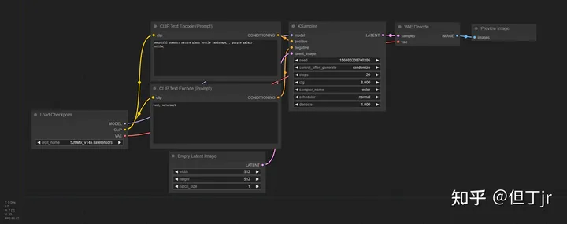
ComfyUI 的默认启动工作流程
在我们运行默认工作流之前,让我们进行一个小修改来预览生成的图像而不保存它们:
.右键单击“Save Image”节点,然后选择“Remove”。
.在画布的空白处双击,输入预览,然后单击“预览图像”选项。
.找到VAE解码节点的IMAGE输出,并将其连接到刚才添加的预览图像节点的images输入。
此修改将预览结果而不会立即将其保存到磁盘。别担心,如果您真的很喜欢某个特定的结果,您仍然可以右键单击图像并选择“保存图像”
通过单击菜单中的“排队提示(Queue Prompt)”或在键盘上按下Cmd+Enter或Ctrl+Enter来创建您的第一张图像,就是这样!
(四)加载其他流程
为了更容易共享,许多稳定扩散接口(包括ComfyUI)会将生成流程的详细信息存储在生成的PNG中。您会发现与ComfyUI相关的许多工作流指南也会包含这些元数据。要加载生成图像的关联流程,只需通过菜单中的“加载”按钮加载图像,或将其拖放到ComfyUI窗口即可。这将自动解析详细信息并加载所有相关节点,包括它们的设置。
如果加载图像但未显示流程,这可能意味着元数据已从文件中剥离。如果您知道图像的原始来源,请尝试要求作者重新上传到不会剥离元数据的网站。
(五)接下来的内容
以上入门的要点应该很好地给您一个Comfy的初始概述。由于基于节点的界面,您可以构建由数十个节点组成的工作流,所有这些节点都在做不同的事情,这允许一些非常酷炫的图像生成流水线。
您现在可能还有很多关于刚才发生的事情的问题,每个节点做什么以及“我如何做X事情”类型的问题。希望这些文档中的其余部分可以回答这些问题。
(六)在线的支持方式(我进去看了,国外的类QQ、微信群)
手册未能回答的其他问题?查看ComfyUI
Matrix空间!ComfyUI
Matrix space!
二、核心节点
(一)高级节点
1.Diffusers Loader
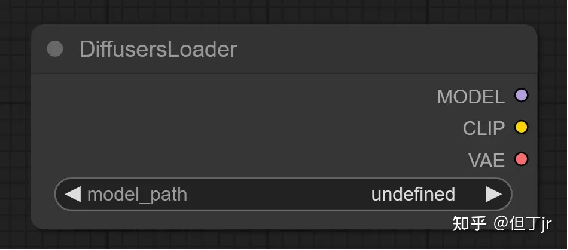
Diffusers Loader节点可以用于加载来自diffusers的扩散模型。
输入:model_path(指向diffusers模型的路径。)
输出:MODEL(用于对潜在变量进行降噪的模型)CLIP(用于对文本提示进行编码的CLIP模型。)
VAE(用于将图像编码至潜在空间,并从潜在空间解码图像的VAE模型。)
示例:示例使用文本与工作流程图
2.Load Checkpoin(with config)【加载Checkpoint(带配置)节点】
"加载检查点(带配置)"节点可以根据提供的配置文件加载扩散模型。请注意,常规的加载检查点节点在大部分情况下能够推测出适当的配置。
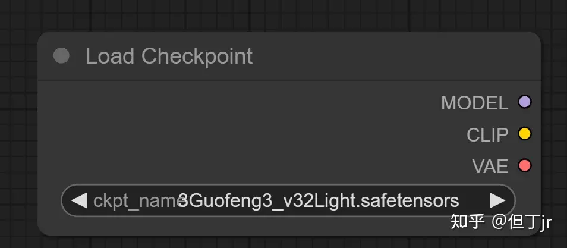
输入:config_name(配置文件的名称)、ckpt_name(要加载的模型的名称);
输出:MODEL(用于去噪潜在变量的模型)、CLIP(用于编码文本提示的CLIP模型)、VAE(用于将图像编码和解码到潜在空间的VAE模型。)
示例:示例使用文本与工作流程图像
(二)Conditioning(条件设定节点)
在 ComfyUI 中,Conditioning(条件设定)被用来引导扩散模型生成特定的输出。所有的Conditioning(条件设定)都开始于一个由 CLIP 进行嵌入编码的文本提示,这个过程使用了 Clip Text Encode 节点。这些条件可以通过本段中找到的其他节点进行进一步增强或修改。
例如,使用 Conditioning (Set Area)、Conditioning (Set Mask) 或 GLIGEN Textbox
Apply 节点,可以引导过程朝着某种组合进行。
或者,通过 Apply Style Model、Apply ControlNet 或 unCLIP Conditioning 节点等,提供额外的视觉提示。相关节点的完整列表可以在侧边栏中找到。
1.Apply ControlNet(应用 ControlNet 节点)
Apply ControlNet 节点能够为扩散模型提供更深层次的视觉引导。不同于
unCLIP 嵌入,controlnets 和 T2I 适配器能在任何模型上工作。通过联接多个节点,我们可以使用多个 controlNets 或 T2I 适配器来引导扩散模型。例如,通过提供一个包含边缘检测的图像和一个在边缘检测图像上训练的 controlNet,我们可以向扩散模型提示在最终图像中的边缘应该在哪里。
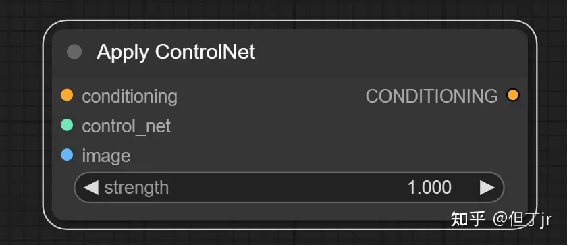
注意:如果你想使用 T2IAdaptor 风格模型,你应该查看Apply Style Model节点。
输入包括conditioning(一个conditioning)、control_net(一个已经训练过的controlNet或T2IAdaptor,用来使用特定的图像数据来引导扩散模型)、image(用作扩散模型视觉引导的图像)。
输出是CONDITIONING,这是一个包含 control_net 和视觉引导的 Conditioning。
示例:示例使用文本和工作流程图像。
2.应用样式模型节点(Apply Style
Model node)
应用风格模型节点可用于为扩散模型(diffusion model)提供进一步的视觉指导,特别是关于生成图像的风格。该节点接收一个T2I风格适配器(style adaptor)模型和一个CLIP视觉模型(CLIP vision model)的嵌入(embedding),以引导扩散模型朝向CLIP视觉模型嵌入的图像风格发展。
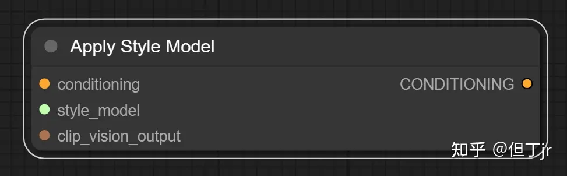
输入包括条件(conditioning)、T2I风格适配器(style_model)、以及一个由CLIP视觉模型编码的包含期望风格的图像(CLIP_vision_output)。条件是一个特定的条件。T2I风格适配器是一个特定的模型,而CLIP视觉模型的输出是一个包含期望风格的图像。
输出是一个包含T2I风格适配器和对期望风格的视觉指导的条件(CONDITIONING)。
示例:示例用法文本与工作流程图像
3.CLIP 设置最后一层节点 (CLIP Set Last
Layer Node)
CLIP 设置最后一层节点 (CLIP Set Last Layer node) [1]用于设置从哪个 CLIP 输出层获取文本嵌入。文本被编码成嵌入的过程是通过 CLIP 模型的多层变换实现的。虽然传统的扩散模型通常根据 CLIP 的最后一层的输出进行条件设定,但有些扩散模型是基于早期层的条件设定的,如果使用最后一层的输出,可能效果不佳。
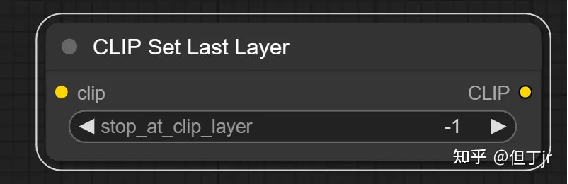
这个节点的输入 (inputs) 是用于编码文本的 CLIP 模型。输出 (outputs) 则是设置了新的输出层的 CLIP 模型。这样,我们可以根据需要,控制从哪一层获取文本嵌入,以适应不同的扩散模型条件。
示例 (example):附有工作流图片的使用示例文本
4.CLIP 文本编码 (Prompt) 节点 (CLIP Text Encode (Prompt) Node)
CLIP 文本编码 (Prompt) 节点可以使用
CLIP 模型将文本提示编码成嵌入,这个嵌入可以用来指导扩散模型生成特定的图片。关于 ComfyUI 中所有文本提示相关特性的完整指南,请参阅Text Prompts页面。
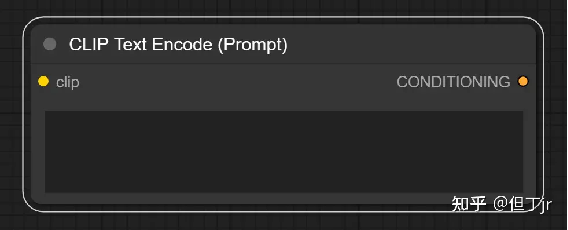
这个节点需要输入一个 CLIP 模型和一个需要被编码的文本。CLIP 模型用于将输入的文本转化为嵌入,而输入的文本则是你希望模型理解并生成相关图片的内容。经过这个节点处理后,你将得到一个包含嵌入文本的条件(Conditioning),这个条件用于指导扩散模型生成图片。
示例 (example):附有工作流图片的使用示例文本。
5.CLIP 视觉编码节点 (CLIP Vision
Encode Node)
CLIP 视觉编码节点用于使用 CLIP 视觉模型将图片编码成嵌入,这个嵌入可以用来指导 unCLIP 扩散模型,或者作为样式模型的输入。
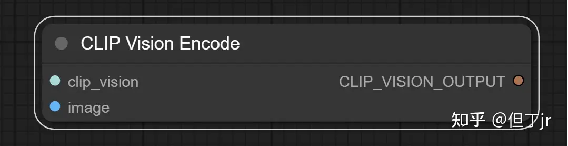
这个节点的输入包括一个用于编码图片的 CLIP 视觉模型和一个需要被编码的图片。CLIP 视觉模型的任务就是将输入的图片转化为嵌入,而输入的图片则是你希望模型理解并进行处理的图像。经过这个节点处理后,将输出编码后的图片。
示例 (example)¶
附有工作流图片的使用示例文本。
6.平均调节 (Conditioning
(Average)) 节点
平均调节节点可以根据在conditioning_to_strength中设置的强度因子,将两个文本嵌入值进行插值处理。
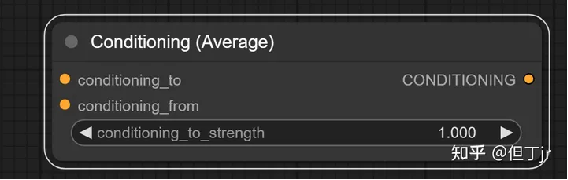
输入参数包括conditioning_to、conditioning_from和conditioning_to_strength。其中conditioning_to是在conditioning_to_strength为1时的调节文本嵌入值,conditioning_from则是在conditioning_to_strength为0时的调节文本嵌入值。conditioning_to_strength是用于控制将conditioning_to混入conditioning_from的混合因子。[2]
输出结果为CONDITIONING,这是一个新的调节文本嵌入值,它根据conditioning_to_strength的设定混合了输入的文本嵌入值。
以下是使用示例和工作流程图。
7.调节(合并)节点
调节(合并)节点(Conditioning (Combine) node)可以通过平均扩散模型的预测噪声来合并多个调节。注意,这与调节(平均)节点(Conditioning (Average) node)是不同的。在这里,对不同调节的扩散模型输出(即构成调节的所有部分)进行平均,而调节(平均)节点则是在调节内部存储的文本嵌入之间进行插值。

提示:虽然调节合并没有一个因子输入来决定如何插值两个结果噪声预测,但调节(设置区域)节点(Conditioning (Set Area) node)可以用来对单个调节进行权重设置,然后再合并它们。
输入包括第一个调节(conditioning_1)和第二个调节(conditioning_2)。输出为一个包含两个输入的新调节(CONDITIONING),稍后将由采样器进行平均。
示例:示例使用文本与工作流程图
8.调节(设置区域)节点
调节(设置区域)节点(Conditioning (Set Area) node)可以用来将调节限制在图像的指定区域内。结合调节(合并)节点(Conditioning (Combine) node),可以增加对最终图像构成的控制。

提示:在ComfyUI中,坐标系统的原点位于左上角。
提示:在混合扩散模型的多个噪声预测时,strength会被归一化。
输入包括将被限制到一个区域的调节(conditioning),区域的宽度(width)、高度(height)、x坐标(x)、y坐标(y),以及在混合多个重叠调节时,要使用的区域的权重(strength)。输出为限制在指定区域的新调节(CONDITIONING)。[3]
示例:示例使用文本与工作流程图
9.调节(设置遮罩)节点
调节(设置遮罩)节点(Conditioning (Set Mask) node)可以用来将调节限制在指定的遮罩内。结合调节(合并)节点(Conditioning (Combine) node),可以增加对最终图像构成的控制。

提示:在混合扩散模型的多个噪声预测时,strength会被归一化[4]。
输入包括将被限制到遮罩的调节(conditioning),约束调节的遮罩(mask),以及在混合多个重叠调节时,要使用的遮罩区域的权重(strength)。还可以设置是否对整个区域进行去噪,或将其限制在遮罩的边界框内(set_cond_area)。输出为限制在指定遮罩内的新调节(CONDITIONING)。
示例:示例使用文本与工作流程图
10.GLIGEN文本框应用节点
GLIGEN文本框应用节点(GLIGEN Textbox Apply node)可以用于为扩散模型提供更进一步的空间指导,引导它在图像的特定区域生成指定的提示部分。虽然文本输入会接受任何文本,但如果输入的是文本提示的一部分对象,GLIGEN的效果最好。[5]
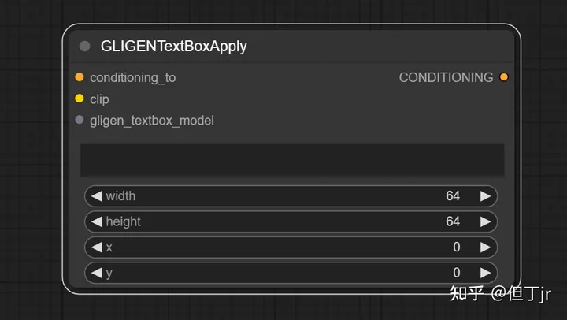
提示:在ComfyUI中,坐标系统的原点位于左上角。
输入包括一个调节(conditioning_to)、一个CLIP模型(clip)、一个GLIGEN模型(gligen_textbox_model)、要关联空间信息的文本(text)、区域的宽度(width)、高度(height)、x坐标(x)和y坐标(y)。输出为包含GLIGEN和空间指导的调节(CONDITIONING)。
示例:示例使用文本与工作流程图
11.unCLIP条件化节点 (unCLIP
Conditioning node)
unCLIP条件化节点 (unCLIP Conditioning node) 能够为unCLIP模型提供额外的视觉引导,通过由CLIP视觉模型编码的图像。这个节点可以串联起来,提供多张图像作为引导。
警告:并非所有的扩散模型都与unCLIP条件化兼容。这个节点特别需要一个考虑到unCLIP的扩散模型。
输入参数包括条件化 (conditioning)、由CLIP视觉模型编码的图像 (clip_vision_output)、unCLIP扩散模型应该受到图像多大的引导 (strength) 以及噪声增强 (noise_augmentation)。噪声增强可以用于引导unCLIP扩散模型随机地在原始CLIP视觉嵌入的邻域里移动,提供与编码图像密切相关的生成图像的额外变化。输出则是一种包含了unCLIP模型额外视觉引导的条件化 (CONDITIONING)。[6]
示例:此处给出使用示例和工作流程图。
(三)实验性功能(这几个节点在Comfyui中应该找不到,可以不看)
实验性功能包含了可能还未完全打磨完成的实验性节点。
1.加载潜变节点 (Load Latent node)
加载潜变[7]节点 (Load Latent node) 可用于加载使用保存潜变节点 (Save Latent node) 保存的潜变。输入参数是要加载的潜变的名称
(latent)。输出参数是加载的潜变图像 (LATENT)。
2.保存潜变节点 (Save Latent node)
保存潜变节点 (Save Latent node) 可用于保存潜变以供后续使用,这些保存的潜变可以通过加载潜变节点 (Load Latent node) 再次加载。输入参数包括要保存的潜变(samples)以及文件名前缀(filename_prefix)。此节点没有输出。
3.Tome补丁模型节点 (Tome Patch Model
node)
Tome补丁模型节点 (Tome Patch Model node) 可用于将Tome优化应用到扩散模型上。Tome (TOken MErging,代表"令牌合并")试图找到一种方法将提示令牌合并,使其对最终图像的影响最小。这将导致生成时间的提升和VRAM需求的降低,但可能会以降低质量为代价。这种权衡可以通过比例设置 (ratio) 来控制,其中更高的值会导致更多的令牌被合并。输入参数包括应用Tome的扩散模型 (model) 和确定何时合并令牌的阈值 (ratio)。输出是经过Tome优化的扩散模型 (MODEL)。
4.VAE 解码(tiled)节点
VAE 解码(瓦片式)节点可用于将潜在空间图像解码回像素空间图像,使用提供的 VAE(变分自编码器)。该节点以瓦片的方式解码潜在图像,使其能够解码比常规 VAE 解码节点更大的潜在图像。
信息:当常规 VAE 解码节点由于
VRAM(视频随机存取存储器)不足而失败时,comfy(一种软件)将自动使用瓦片式实现进行重试。
输入参数为待解码的潜在图像和用于解码潜在图像的 VAE。输出结果是解码后的图像。
5.VAE 编码(tiled)节点
VAE 编码(瓦片式)节点可用于将像素空间图像编码为潜在空间图像,使用提供的 VAE(变分自编码器)。该节点以瓦片的方式编码图像,使其能够编码比常规 VAE 编码节点更大的图像。
信息:当常规 VAE 编码节点由于
VRAM(视频随机存取存储器)不足而失败时,comfy将自动使用瓦片式实现进行重试。
输入参数为待编码的像素空间图像和用于编码像素图像的 VAE。输出结果是编码后的潜在图像。
(四)Image(图像)
ComfyUI 提供了各种节点来操作像素图像。这些节点可以用于加载 img2img(图像到图像)工作流程的图像,保存结果,或者例如,为高分辨率工作流程放大图像。
1.图像反转节点(Invert Image)【我没有这个节点,不知道为什么】
图像反转节点可以用来反转图像的颜色。
输入参数为待反转的像素图像。输出结果是反转后的像素图像。
2.加载图像节点
加载图像节点可用于加载图像。可以通过启动文件对话框或将图像拖放到节点上来上传图像。一旦图像被上传,它们可以在节点内部被选择。
信息:默认情况下,图像将被上传到 ComfyUI 的输入文件夹。
输入参数为待使用的图像名称。输出结果是像素图像和图像的 alpha 通道。
示例:为了执行图像到图像的生成,你需要使用加载图像节点来加载图像。在下面的例子中,一个图像是使用加载图像节点加载的,然后被一个 VAE 编码节点编码到潜在空间,让我们能够执行图像到图像的任务。
3."Pad Image for
Outpainting"(为外部绘画填充图像)节点
"Pad Image for Outpainting"(为外部绘画填充图像)节点可用来为外部绘画的图像添加填充,然后将此图像通过"VAE Encode for Inpainting"(为内部绘画编码的变分自动编码器)传递给修复扩散模型。[8]
输入包括图像、左侧、上方、右侧、底部以及羽化。图像是需要被填充的图像。左侧、上方、右侧以及底部分别描述了图像各边需要填充的量。羽化则用于描述原始图像边缘的柔化程度。输出包括被填充的像素图像(IMAGE)和一个用于指示采样器在何处进行外部绘画的遮罩(MASK)。
4."Preview
Image"(预览图像)节点
"Preview Image"(预览图像)节点可以用来在节点图内预览图像。输入是需要预览的像素图像。这个节点没有输出。
5."Save
Image"(保存图像)节点
"Save Image"(保存图像)节点可以用来保存图像。如果你只是想在节点图内预览图像,可以使用"Preview Image"(预览图像)节点。当你生成的图像过多,难以跟踪管理时,你可以通过一个带有文件前缀小部件的输出节点传递特殊格式的字符串来帮助组织你的图像。关于如何格式化你的字符串的更多信息,你可以查看Save File Formatting的相关内容。
输入包括需要预览的像素图像,以及一个要放入文件名中的前缀。这个节点没有输出。
6.图像混合(Image Blend)节点
图像混合(Image Blend)节点用于将两个图像融合在一起。
信息:如果第二个图像的尺寸不符合第一个的尺寸,它将被重新缩放并居中裁剪以维持其纵横比
输入参数包括第一个像素图像(image1)、第二个像素图像(image2)、第二个图像的透明度(blend_factor)及图像混合方式(blend_mode)。输出则是混合后的像素图像(IMAGE)。
7.图像模糊(Image Blur)节点
图像模糊(Image Blur)节点可以用来对图像应用高斯模糊(Gaussian blur)。
输入(inputs)包括图片(image),这是需要被模糊化的像素图像,高斯半径(blur_radius),以及高斯的西格玛(sigma),西格玛越小,核就越集中在中心像素。输出(outputs)则是模糊化后的像素图像(IMAGE)。
8.图像量化(Image Quantize)节点
图像量化(Image Quantize)节点可以用来对图像进行量化处理,减少图像中的颜色数量。
输入(inputs)包括图片(image),这是需要被量化的像素图像,颜色(colors),即量化图像中的颜色数量,以及抖动(dither),即是否使用抖动技术使量化图像看起来更平滑。输出(outputs)则是量化后的像素图像(IMAGE)。
9.图像锐化(Image Sharpen)节点
图像锐化(Image Sharpen)节点可以用来对图像应用拉普拉斯锐化滤波器(Laplacian sharpening filter)。
输入(inputs)包括图片(image),即需要被锐化的像素图像,锐化半径(sharpen_radius),即锐化核的半径,高斯西格玛(sigma),西格玛越小,核就越集中在中心像素,以及锐化强度(alpha),即锐化核的强度。输出(outputs)则是锐化后的像素图像(IMAGE)。
10使用模型放大图像(Upscale Image
(using Model))节点
使用模型放大图像(Upscale Image (using Model))节点可以用来通过加载放大模型(Load Upscale Model)节点中的模型来放大像素图像。
输入(inputs)包括用于放大的模型(upscale_model)和需要被放大的像素图像(image)。输出(outputs)则是放大后的图像(IMAGE)。
(五)潜在模型(Latent)
像稳定扩散(Stable Diffusion)这样的潜在扩散模型并不在像素空间中操作,而是在潜在空间中进行去噪处理。这些节点提供了使用编码器和解码器在像素空间和潜在空间之间切换的方法,并提供了多种操控潜在图像的方式。
1.空潜在图像(Empty Latent Image)节点
空潜在图像(Empty Latent Image)节点可以用来创建一组新的空白潜在图像。这些潜在图像可以被例如在text2image工作流中通过采样器节点进行噪声处理和去噪后使用。
输入(inputs)包括潜在图像的像素宽度(width)和像素高度(height),以及潜在图像的数量(batch_size)。输出(outputs)则是空白的潜在图像(LATENT)。
2.潜在复合(Latent Composite)节点
潜在复合(Latent Composite)节点可以用来将一个潜在图像粘贴到另一个中。
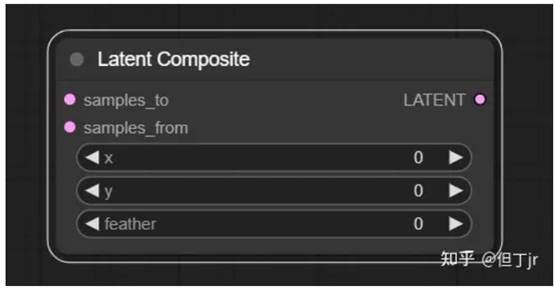
信息(Info):在ComfyUI中,坐标系统的原点位于左上角。
输入(inputs)包括需要被粘贴的潜在图像(samples_to),需要粘贴的潜在图像(samples_from),粘贴潜在图像的x坐标(x)和y坐标(y),以及需要粘贴的潜在图像的羽化程度(feather)。输出(outputs)则是一个包含了粘贴样本(samples_from)的新的潜在复合(LATENT)。
3.潜在复合遮罩(Latent Composite
Masked)节点
潜在复合遮罩(Latent Composite Masked)节点可以用来将一个遮罩的潜在图像粘贴到另一个中。
信息(Info):在ComfyUI中,坐标系统的原点位于左上角。
输入(inputs)包括需要被粘贴的潜在图像(destination),需要粘贴的遮罩潜在图像(source),遮罩(mask),以及粘贴潜在图像的x坐标(x)和y坐标(y)。输出(outputs)则是一个包含了粘贴的源潜在图像(source)的新的潜在复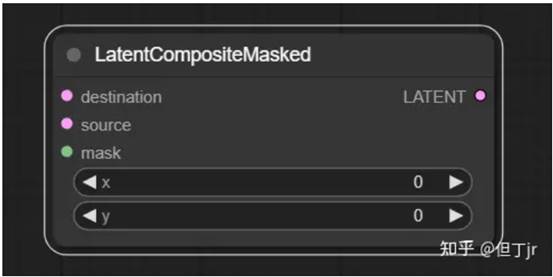 合(LATENT)。
合(LATENT)。
4.放大潜在图像(Upscale Latent)节点
放大潜在图像(Upscale Latent)节点可以用来调整潜在图像的大小。

警告(Warning):调整潜在图像的大小与调整像素图像的大小并不相同。直接调整潜在图像而不是像素可能会导致更多的图像失真。
输入(inputs)包括需要被放大的潜在图像(samples),用于调整大小的方法(upscale_method),目标像素宽度(Width)和目标像素高度(height),以及是否通过中心裁剪(crop)图片以保持原始潜在图像的长宽比。输出(outputs)则是调整大小后的潜在图像(LATENT)。
5.VAE解码(VAE Decode)节点
VAE解码(VAE Decode)节点可以用来将潜在空间图像解码回像素空间图像,解码过程使用提供的变分自编码器(VAE)。
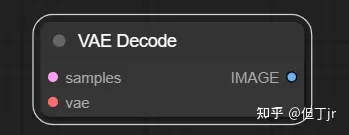
输入(inputs)包括需要被解码的潜在图像(samples)以及用于解码潜在图像的变分自编码器(VAE)。输出(outputs)则是解码后的图像(IMAGE)。
示例(example)¶
待做:SD 1.5至XL的示例
6.VAE编码(VAE Encode)节点
VAE编码(VAE Encode)节点可以用来将像素空间图像编码成潜在空间图像,编码过程使用提供的变分自编码器(VAE)。
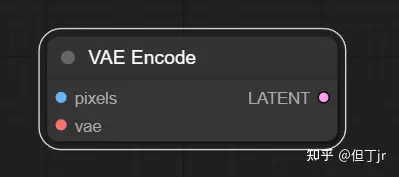
输入(inputs)包括需要被编码的像素空间图像(pixels)和用于编码像素图像的变分自编码器(VAE)。输出(outputs)则是编码后的潜在图像(LATENT)。[9]
示例(example):为了在例如图像到图像的任务中使用图像,它们首先需要被编码成潜在空间。在下面的示例中,VAE编码节点被用来将一个像素图像转换成一个潜在图像,这样我们就可以对这个图像进行重新噪声处理和去噪,从而创造出新的图像。
7-1."Latent From
Batch"节点
可以用于从一批潜在图像中提取一个切片。当需要在工作流中分离出特定的潜在图像或图像批次时,这将非常有用。
输入参数包括样本(samples,即要提取切片的一批潜在图像),批次索引(batch_index,即要提取的第一张潜在图像的索引),以及长度(length,即要取的潜在图像的数量)。输出结果是LATENT(新的只包含所选切片的潜在图像批次)。
7-2.Rebatch Latents节点
Rebatch Latents节点用于拆分或合并一批潜在图像的批次。当结果为多个批次时,该节点会输出一个批次列表,而不是单个批次。这在批次大小超过VRAM(视频随机存取内存)容量时非常有用,因为ComfyUI会按列表中的每个批次执行节点,而不是一次性执行。该节点也可用于将批次列表合并回单个批次。[10]
信息:此节点的输出为列表,请阅读此页面以获取有关在comfy中列表的更多信息。待办事项:找出何时何地解释这个。
输入与输出说明:输入"样本"是需要重新分批的潜在图像,"批大小"是新的批次大小。输出"LATENT"是一个潜在图像的列表,其中每个批次的大小不超过"批大小"。
7-3.Repeat Latent
Batch节点
Repeat Latent Batch节点用于重复一批潜在图像。例如,这可以在图像到图像的工作流中用来创建图像的多个变体。
输入与输出说明:输入"样本"是要重复的潜在图像的批次,"数量"是重复的次数。输出"LATENT"是新的一批潜在图像,将原批次重复了设定的次数。
8-1【Inpaint】"Set Latent Noise Mask"节点
可以用于为用于修复的潜在图像添加遮罩。设定噪声遮罩后,采样器节点只会在遮罩区域进行操作。如果提供了单一遮罩,批次中的所有潜在图像都会使用这个遮罩。
输入参数包括样本(samples,即待修复并添加遮罩的潜在图像),以及遮罩(mask,指示修复位置的遮罩)。输出结果是LATENT(经过遮罩处理的潜在图像)。
8-2【inpaint】"VAE Encode For Inpainting"节点
"VAE Encode For Inpainting"节点可以使用所提供的变分自编码器(VAE)将像素空间的图像编码成潜在空间的图像,并接受一个用于修复的遮罩,向采样器节点指示应去噪的图像部分。通过`grow_mask_by`可以增加遮罩的区域,为修复过程提供一些额外的填充空间。
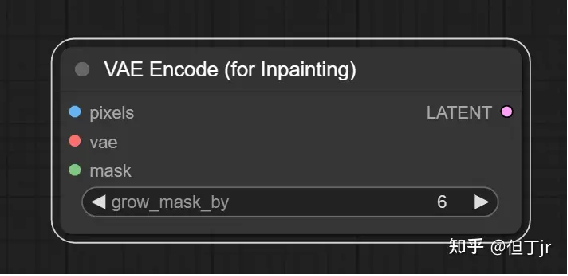
这个节点特别设计用于为修复训练的扩散模型,并确保编码前遮罩下的像素被设为灰色(0.5,0.5,0.5)。
输入参数包括像素(pixels,即待编码的像素空间图像),VAE(用于编码像素图像的变分自编码器),遮罩(mask,指示修复位置的遮罩),以及`grow_mask_by`(用于增加给定遮罩区域的量)。输出结果是LATENT(遮罩处理并编码后的潜在图像)。
9-1【Transform】"Crop Latent"节点
"Crop Latent"节点可以用来将潜在图像裁剪到新的形状。
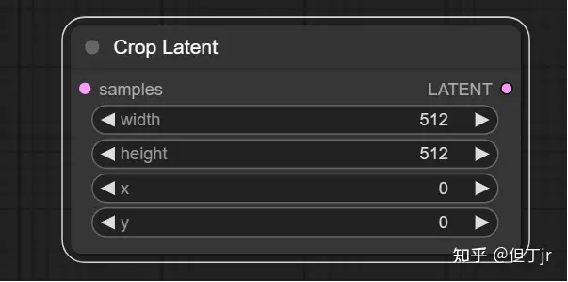
需要注意的是,ComfyUI中的坐标系统原点位于左上角。
输入参数包括样本(samples,即待裁剪的潜在图像),宽度(width,裁剪区域的像素宽度),高度(height,裁剪区域的像素高度),以及x和y(区域的像素坐标)。输出结果是LATENT(裁剪后的潜在图像)。
9-2【Transform】"Flip Latent"节点
"Flip Latent"节点可以用来将潜在图像进行水平翻转或垂直翻转。
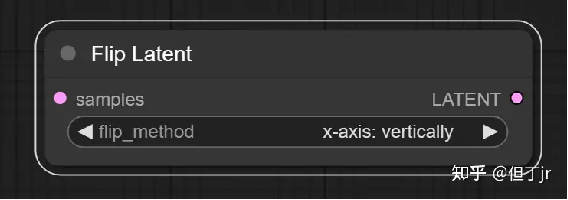
输入参数包括样本(samples,即待翻转的潜在图像),以及翻转方法(flip_method,即是水平翻转还是垂直翻转)。输出结果是LATENT(翻转后的潜在图像)。
9-3【Transform】"Rotate Latent"节点
"Rotate Latent"节点可以用于将潜在图像以90度的增量顺时针旋转。
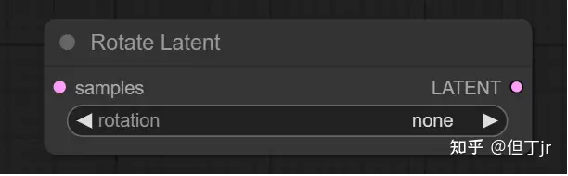
输入参数包括样本(samples,即要旋转的潜在图像),以及旋转(rotation,指定顺时针旋转的角度)。输出结果是LATENT(旋转后的潜在图像)。
(六)Loaders,加载器
本段中的加载器可以用来加载各种工作流中使用的模型。所有加载器的完整列表可以在侧边栏中找到。
1.GLIGEN Loader
"GLIGEN Loader"[11]节点可以用于加载特定的GLIGEN模型。GLIGEN模型用于将空间信息关联到文本提示的部分,引导扩散模型按照GLIGEN指定的组合生成图像。
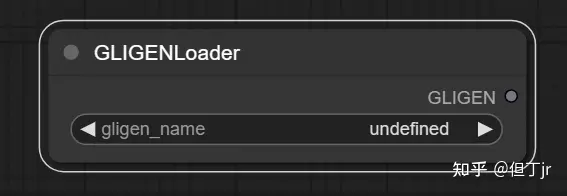
输入参数是GLIGEN模型的名称(gligen_name)。输出结果是GLIGEN模型(用于将空间信息编码到文本提示部分的模型)。
2.Hypernetwork Loader
Hypernetwork Loader 节点可用于加载超网络。与 LoRAs 类似,它们用于修改扩散模型,以改变潜在因素的去噪方式。典型的用例包括向模型添加生成某种风格的能力,或更好地生成某些主题或动作。甚至可以将多个超网络链接在一起以进一步修改模型。
提示:超网络强度值可以设置为负值。有时这可能会产生有趣的效果。
输入:
·model:一个扩散模型。
·hypernetwork_name:超网络的名称。
·strength:如何强烈地修改扩散模型。此值可以为负。
输出:
·MODEL:修改后的扩散模型。
3.Load CLIP
Load CLIP 节点可用于加载特定的 CLIP 模型。CLIP
模型用于编码指导扩散过程的文本提示。
警告:条件扩散模型是使用特定的 CLIP 模型进行训练的,使用与其训练时不同的模型不太可能产生好的图像。Load
Checkpoint 节点会自动加载正确的 CLIP 模型。
输入:
·clip_name:CLIP 模型的名称。
输出:
·CLIP:用于编码文本提示的 CLIP 模型。
4.Load CLIP Vision
Load CLIP Vision 节点可用于加载特定的 CLIP 视觉模型。与 CLIP 模型用于编码文本提示的方式类似,CLIP 视觉模型用于编码图像。
输入:
·clip_name:CLIP 视觉模型的名称。
输出:
·CLIP_VISION:用于编码图像提示的 CLIP 视觉模型。
5.Load Checkpoint
Load Checkpoint 节点可用于加载扩散模型,扩散模型用于去噪潜在因素。此节点还将提供适当的 VAE 和 CLIP 模型。
输入:
·ckpt_name:模型的名称。
输出:
·MODEL:用于去噪潜在因素的模型。
·CLIP:用于编码文本提示的 CLIP 模型。
·VAE:用于将图像编码和解码到潜在空间的 VAE 模型。
6.Load ControlNet
Model
Load ControlNet Model 节点可用于加载 ControlNet 模型。与 CLIP 模型提供一种给予文本提示以指导扩散模型的方式类似,ControlNet 模型用于为扩散模型提供视觉提示。这个过程与例如给扩散模型一个部分噪声的图像进行修改的方式不同。相反,ControlNet 模型可以用来告诉扩散模型例如最终图像中的边缘应该在哪里,或者主体应该如何摆放。此节点还可用于加载 T2IAdaptors。
输入:
·control_net_name:ControlNet 模型的名称。
输出:
·CONTROL_NET:用于为扩散模型提供视觉提示的 ControlNet 或 T2IAdaptor 模型。
7.Load LoRA
Load LoRA 节点可用于加载 LoRA。LoRAs 用于修改扩散和 CLIP 模型,以改变潜在因素的去噪方式。典型的用例包括向模型添加生成某种风格的能力,或更好地生成某些主题或动作。甚至可以将多个 LoRAs 链接在一起以进一步修改模型。
提示:LoRA
强度值可以设置为负值。有时这可能会产生有趣的效果。
输入:
·model:一个扩散模型。
·clip:一个 CLIP 模型。
·lora_name:LoRA 的名称。
·strength_model:如何强烈地修改扩散模型。此值可以为负。
·strength_clip:如何强烈地修改 CLIP 模型。此值可以为负。
输出:
·MODEL:修改后的扩散模型。
·CLIP:修改后的 CLIP 模型。
8.Load Style Model
Load Style Model 节点可用于加载风格模型。风格模型可以用于为扩散模型提供关于去噪潜在因素应该采用的风格的视觉提示。
信息:目前只支持 T2IAdaptor 风格模型。
输入:
·style_model_name:风格模型的名称。
输出:
·STYLE_MODEL:用于为扩散模型提供关于所需风格的视觉提示的风格模型。
9.Load Upscale Model
Load Upscale Model 节点可用于加载特定的放大模型,放大模型用于放大图像。
输入:
·model_name:放大模型的名称。
输出:
·UPSCALE_MODEL:用于放大图像的放大模型。
10.Load VAE
Load VAE 节点可用于加载特定的 VAE 模型。VAE
模型用于将图像编码和解码到潜在空间。尽管 Load Checkpoint 节点提供了一个 VAE 模型和扩散模型,但有时使用特定的 VAE 模型可能会很有用。
输入:
·vae_name:VAE 的名称。
输出:
·VAE:用于将图像编码和解码到潜在空间的 VAE 模型。
示例: 有时您可能希望使用与随节点加载的 VAE 不同的 VAE。在下面的示例中,我们使用不同的 VAE 将图像编码到潜在空间,并解码 Ksampler 的结果。
11.unCLIP Checkpoint
Loader
unCLIP Checkpoint Loader 节点可用于加载专为与 unCLIP 一起工作而制作的扩散模型。unCLIP 扩散模型用于去噪潜在因素,这些潜在因素不仅基于提供的文本提示,还基于提供的图像。此节点还将提供适当的 VAE、CLIP 和 CLIP 视觉模型。
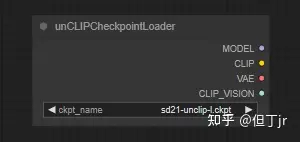
警告:尽管此节点可用于加载所有扩散模型,但并非所有扩散模型都与 unCLIP 兼容。
输入:
·ckpt_name:模型的名称。
输出:
·MODEL:用于去噪潜在因素的模型。
·CLIP:用于编码文本提示的 CLIP 模型。
·VAE:用于将图像编码和解码到潜在空间的 VAE 模型。
·CLIP_VISION:用于编码图像提示的 CLIP 视觉模型。
(七)mask
遮罩为采样器提供了一种方法,告诉它哪些部分应该去噪,哪些部分应该保持原样。这些节点提供了各种方法来创建或加载遮罩并对其进行操作。
1.convert image to
mask
"Convert Image to Mask" 节点可以用来将图像的特定通道转换为遮罩。
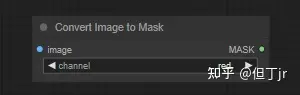
输入:
·image:要转换为遮罩的像素图像。
·channel:要用作遮罩的通道。
输出:
·MASK:从图像通道创建的遮罩。
2.convert mask to image
"Convert Mask to Image" 节点可以用来将遮罩转换为灰度图像。
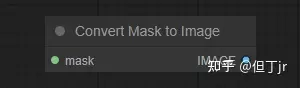
输入:
·mask:要转换为图像的遮罩。
输出:
·IMAGE:从遮罩生成的灰度图像。
3.crop mask
"Crop Mask" 节点可以用来将遮罩裁剪成新的形状。
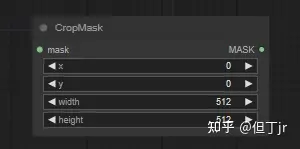
信息:
ComfyUI 中的坐标系统原点位于左上角。
输入:
·mask:要裁剪的遮罩。
·width:区域的像素宽度。
·height:区域的像素高度。
·x:区域的
x 坐标(以像素为单位)。
·y:区域的
y 坐标(以像素为单位)。
输出:
·MASK:裁剪后的遮罩。
4.feather mask
5.invert mask
6.load image(as mask)
7.mask composite
8.solid mask
参考
.^CLIP 设置最后一层节点 (CLIP Set Last Layer Node) 就像是一个控制器,它可以帮我们决定从哪一层的 CLIP 模型中提取我们需要的文本信息。你可以把 CLIP 模型想像成一个大楼,每一层都有不同的信息。这个节点就是电梯调度员,可以帮助我们选择去到哪一层获取信息。
传统上,我们会从最顶层(最后一层)获取信息,因为那里的信息是最完整、最精炼的。但是,在某些情况下,一些特定的模型可能需要从较低的楼层(早期的层)获取信息,因为这些较早的层可能包含有更原始或更具体的信息。这就像有些人可能需要去大楼的档案室(早期的层)而不是总裁办公室(最后一层)来找他们需要的信息。
在这个节点中,你需要输入一个 CLIP 模型,然后它会按照你的指示,从正确的层次中获取信息,然后输出一个新的、已经设置好输出层的 CLIP 模型。
.^一个关于文本输入提示词的例子。 假设我们有两个输入提示词: 输入提示词A: "写一个关于快乐的故事。"(对应 conditioning_from) 输入提示词B: "写一个关于悲伤的故事。"(对应 conditioning_to) 我们想要生成一个新的提示词,它在语义上介于输入提示词A和输入提示词B之间。conditioning_to_strength 决定了新的提示词的语义更接近哪一个原始提示词。
如果 conditioning_to_strength 设置为0,新的提示词将完全是 "写一个关于快乐的故事。",与输入提示词A的语义相同。 如果 conditioning_to_strength 设置为1,新的提示词将完全是 "写一个关于悲伤的故事。",与输入提示词B的语义相同。 如果 conditioning_to_strength 设置为0.5,新的提示词可能是 "写一个关于淡淡忧伤的故事。",这在语义上介于输入提示词A和输入提示词B之间。
.^让我们假设你正在使用一个扩散模型来生成一个图像,这个图像需要包含两种不同的元素:一只猫和一个篮球。你可以创建两个不同的调节,一个用于猫,一个用于篮球。然后,你可以使用调节(合并)节点(Conditioning (Combine) node)来将这两个调节合并成一个。 但是,你想要更精确地控制这两个元素在最终图像中的位置。这就是调节(设置区域)节点(Conditioning (Set Area) node)派上用场的地方。你可以使用这个节点来限制猫和篮球的调节在图像的特定区域。例如,你可以设置猫的调节在图像的左侧,篮球的调节在图像的右侧。
此外,你还可以使用“strength”输入来控制当这两个调节有重叠时,如何混合它们。如果你希望在重叠区域更多地显示猫,你可以为猫的调节设置较高的“strength”。 这样,你就可以更精确地控制最终图像的构成,而不仅仅是将两个调节简单地合并在一起。
.^"strength is normalized before mixing
multiple noise predictions from the diffusion model." 这句话的意思是,在混合扩散模型的多个噪声预测之前,会对
strength 进行归一化处理。 这里的 "归一化"
是一种常见的数据预处理技术,它的目的是将数据转换到一个公共的尺度上,通常是在 0 到 1 之间。在这个上下文中,strength 归一化意味着当你有多个重叠调节,每个调节的 strength 值将被重新调整,使得所有 strength 的总和为 1。 举个例子,假设你有两个重叠的调节,每个调节的 strength 分别为 0.6 和 0.4。在进行归一化处理后,这两个 strength 值的总和就变为 1(0.6
+ 0.4 = 1)。这样做的好处是,无论你有多少重叠的调节,或者这些调节的 strength 值是多少,混合后的结果都会保持在一个合理的范围内,不会因为某个调节的 strength 值过大而导致其它调节被压制。
.^举个例子,假设你想生成一幅包含"猫"和"篮球"的图像,你可能会为模型提供一个提示,比如"一只猫在玩篮球"。然而,这个提示并没有告诉模型猫和篮球应该在图像的哪个位置。这就是GLIGEN文本框应用节点派上用场的地方,你可以用它来指导模型在图像的特定区域生成"猫"和"篮球"。
例如,你可能会设置一个文本框,文本为"猫",位置在图像的左上角,然后设置另一个文本框,文本为"篮球",位置在图像的右下角。这样,模型在生成图像时就会尽可能地让"猫"出现在左上角,"篮球"出现在右下角。
.^为了更具体地理解这个节点的输入和输出,让我们想象一个具体的例子。假设你是一个画家,你正在画一张风景画,你有一张照片作为参考(这就是由CLIP视觉模型编码的图像,也就是输入中的clip_vision_output)。"引导强度"(strength)就像是你对这张照片的依赖程度,如果你完全依赖这张照片,那么你画出来的画可能就完全复制这张照片;如果你只是稍微参考一下,那么你的画可能就会有很多创新和变化。"噪声增强"(noise_augmentation)就像是你想要在画中加入一些未在照片中出现的元素,比如你可能会在画中加入一些照片中没有的树或者云彩,这样可以让你的画更具有个性和创新性。
最后,输出的"调节度"(CONDITIONING)就是你最终画出的画,这幅画被你的照片(clip_vision_output)、你对照片的依赖程度(strength)以及你添加的新元素(noise_augmentation)所影响和指导。
.^在深度学习和机器学习中,"潜变"或"潜在变量"(Latent)通常用来指那些我们无法直接观察到,但可以通过数据和模型推断出来的变量或特征。这些潜在变量通常包含了数据的重要信息,比如一张图片中的对象、颜色或样式等。
让我们用一个更具体的例子来解释。假设你有一堆关于人们的数据,包括他们的年龄、性别、收入等可观察的特征。但你想知道的是他们是否喜欢运动,这是一个你无法直接从数据中观察到的特征,它就是一个"潜在"的特征。你可能需要通过分析他们的年龄、性别、收入等可观察的特征来推断他们是否喜欢运动。
在生成模型(如GANs,生成对抗网络)中,"潜在空间"通常指的是一个多维空间,模型从这个空间中抽取向量(被称为"潜在向量"或"潜变"),然后通过模型转化为我们可以观察到的数据,如图像、音频等。比如,一个绘画机器人可能会从潜在空间中抽取一个潜在向量,然后转化为一幅画。这个潜在向量可能包含了画的风格、颜色、对象等信息。
.^举个例子,假设你有一张照片,只拍到了树的一部分,而你想通过外部绘画技术来完整地展现整棵树。首先,你会使用这个节点为这张照片添加填充,也就是在照片的边缘添加一些空白区域。然后,你会通过"VAE Encode for Inpainting"(为内部绘画编码的变分自动编码器)把这张带有填充的照片送入修复扩散模型。这个模型会根据照片中树的部分信息,推测并绘制出树的剩余部分在填充区域中应该是什么样子。
当你在设置这个节点时,你需要提供一些参数。比如,左、右、上、下参数让你指定在图像的哪个方向以及多少空间进行填充。"羽化"参数则用于设置在原图与填充空间交界处,如何平滑过渡,以使得绘画看起来更自然。 输出的结果包括被填充的像素图像,以及一个"遮罩"。这个遮罩就像一个指南,告诉修复扩散模型应该在哪些地方进行外部绘画。
.^假设你有一盒彩色笔记本,这些笔记本就像潜在图像批次(samples),每一个笔记本就像一个潜在图像。这一盒子里面有红色、蓝色、绿色、黄色等各种颜色的笔记本。现在,你想要拿出几本特定颜色的笔记本,比如从第三本开始,拿出两本。这就相当于"batch_index"是3(我们从第三本开始拿),"length"是2(我们要拿两本)。 从批次获取潜在图像(Latent From Batch)节点就像是你的手,帮你准确地从这一大堆笔记本中找到并拿出你想要的那几本。然后,你手中的这几本笔记本就是输出(outputs),也就是新的潜在图像批次(LATENT),它只包含你刚才挑选出来的那几本笔记本。
.^你可以把VRAM想象成你的书包。你的书包只能装下一定数量的书,这就像VRAM只能装下一定数量的潜在图像。如果你的书太多,书包装不下,你就需要把书分成几堆,然后一次只拿一堆书。 这就是"Rebatch Latents节点"的作用。假设你有100个潜在图像(就像你有100本书),但是你的VRAM(你的书包)一次只能装10个(10本书)。那么,这个节点就会把这100个潜在图像分成10个批次(就像把100本书分成10堆),每个批次只有10个(每堆只有10本书)。这样,你就可以一次处理一个批次(一次只拿一堆书),不会超过你的VRAM(书包)的容量。 另一方面,如果你有很多小批次的潜在图像(就像你有很多堆只有一两本书的书堆),你想把它们都放进一个大批次(就像你想把所有的书都放进一个大书包)。这个节点也可以帮助你做到这一点,只要确保合并后的批次(大书包)的大小不超过你的VRAM(书包)的容量。
.^好的,我来系统地总结一下GLIGEN的概念: 1. 定义
GLIGEN全称是Guided Language-Image GENeration,表示通过语言/文本指导和控制来生成图像的方法。 2. 工作流程 (1) 使用自然语言描述场景和对象的布局、位置关系等,例如“一个女孩站在海边”。 (2) GLIGEN中的空间解析器会分析这些语言描述,转换为空间布局配置信息,如为“女孩”确定中心位置,为“海边”确定背景位置。 (3) 空间编码器将解析得到的空间信息编码到文本提示词中,为每个词语添加空间坐标。 (4) 在图像生成时,解码器会利用这些空间编码,使得生成的内容遵循语言描述的空间布局。 (5) 迭代生成时,使用上一步的空间信息进行位置自回归,确保一致的空间结构。 3. 优点 相较于仅使用文本提示,GLIGEN可以更精确地控制图像的布局和组成,使得生成的图像更符合语言描述,达到文字与图像高度一致。 4. 在Stable Diffusion中的应用 在Stable Diffusion中,GLIGEN被集成为一个模块,可以解析文本描述生成空间信息,并控制生成过程,从而大大提高了Stable Diffusion对图像布局控制的能力。 5. 总结 GLIGEN利用语言指导图像生成,是文本到图像生成的重要扩展,可以生成更精确、结构合理的图像。它极大提升了图像生成的控制能力。
出自:https://zhuanlan.zhihu.com/p/648278481
GPTBots让开发者及企业将 LLM 与自己的数据、应用服务无缝连接,轻松构建 AI 服务,平台来自极光(Aurora Mobile,纳斯达克股票代码:JG)。