现在LLM 的大小为什都设计成6/7B、13B和130B几个档次?
发布时间:2024年06月06日
链接:https://www.zhihu.com/question/627258986/answer/3260798103
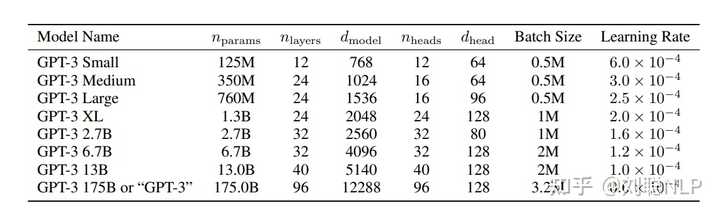
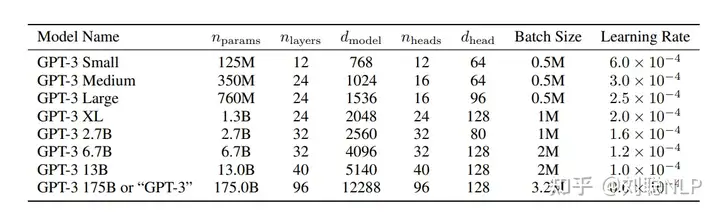
LLM现在一般都是基于Transormer结构,参数总和可以看作Embedding部分参数和Transormer-Decoder部分参数,Embedding部分参数由词表大小和模型维度决定;Decoder部分参数由模型层数和模型维度决定。
因此决定参数的几个因素有:词表大小、模型层数(深度)、模型维度(宽度)。
关于词表大小设置,越大的词表的压缩会更好,但可能导致模型训练不充分;越小的词表压缩会比较差,导致模型对长度需求较高。Qwen技术报告和BaiChuan2技术报告中都有相关内容介绍。
关于层数设置问题,其实模型层数和维度具体设置成多少是最优的(但一般层数变大,维度也会变大),目前好像没有论文明确表明,但绝大多数感觉跟着GPT3的层数和维度来的。
所以你可以看到常见的模型6/7B是32层、13B是40层。
PS:可能由于GPT3模型先出的,让OPT、Bloom等都是为了做开源的GPT3所提出的,因此参数规模是一致的。后面的llama也是为了对标GPT3,不过为了证明效果更好,也在中间多了33B和65B规模。130B貌似只有GLM大模型是这个参数。
现在流传甚广的其实是6/7B(小)、13B(中),主要是由于更大的模型训练成本会更高,并且对于很多人来说13B的模型已经算顶配了(消费显卡跑得了),再大的模型,对于个人来说也是负担。
画本妖鸡,多人有声剧文本处理协作系统,专为主播定制的阅读器。