Stable Diffusion AnimateDiff | 最稳定的基于文本生成视频的方法!
发布时间:2024年06月06日
今天给大伙分享一下目前来看比较稳定的文本生视频的插件AnimateDiff。
之前虽然小视频生成比较火,不过出的视频都不太稳定,目前来看AnimateDiff是相对比较稳定的,而且能同时支持和其他插件一起使用。
一 AnimateDiff 介绍
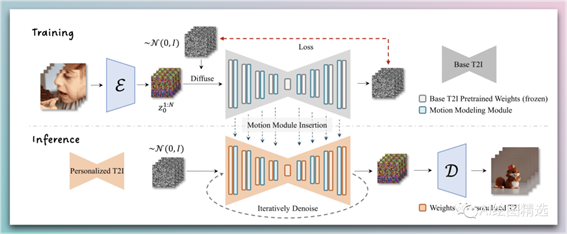
AnimateDiff 使用控制模块来影响
Stable Diffusion 模型。它通过各种短视频剪辑进行训练。控制模块可以对图像生成过程进行调节,以生成一系列看起来像它学习的视频剪辑的图像。
简单来说,SD 模型的训练是通过大量的图片进行训练。而 AnimateDiff 则是通过大量的短视频来进行训练图片之间的衔接(视频帧的流畅性)
结合 SD 模型,在出图的时候就可以通过 AnimateDiff 模型对生成出的每一张图进行微调,最后拼接成短视频。
二 安装
使用 AnimateDiff 需要安装 SD 插件和 AnimateDiff 模型。
插件安装
如果你能科学上网,那么可以直接在扩展->从网址安装 中填入https://github.com/continue-revolution/sd-webui-animatediff.git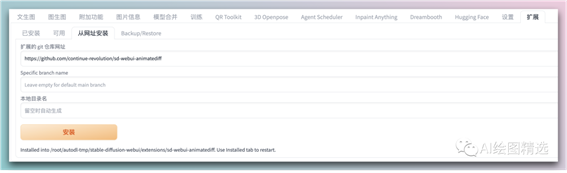
如果你没办法通过网站安装,安装包也给大家准备好了,公众号回复插件获取sd-webui-animatediff压缩包,解压到你的 SD 安装目录下的stable-diffusion-webui/extensions/
模型下载
安装好插件之后,将 AnimateDiff 模型下载放到stable-diffusion-webui/extensions/sd-webui-animatediff/model/
下载链接:https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15_v2.ckpt
同样如果没办法下载的话,公众号回复模型找到mm_sd_v15_v2.ckpt放到本地的目录中即可。
安装成功之后,重启 Stable Diffusion,在文生图页面可以看到 AnimateDiff 插件配置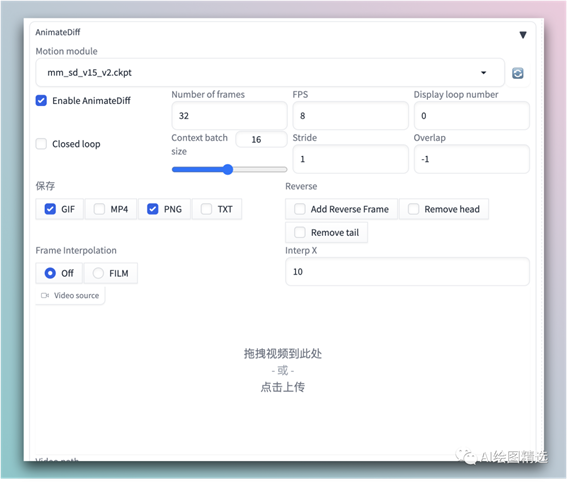
三 视频生成
第一步:先填写基础信息
模型:majicmixRealistic_v6
提示词:((pure white background )),Best quality,masterpiece,ultra high res,raw photo,beautiful and aesthetic,(photorealistic:1.4),1girl,full-body composition,striking perspective
Danceing,
high-waisted shorts,,ruffled blouse
反向提示词:FastNegativeV2 EasyNegative
其它的先使用默认的第二步:配置AnimateDiff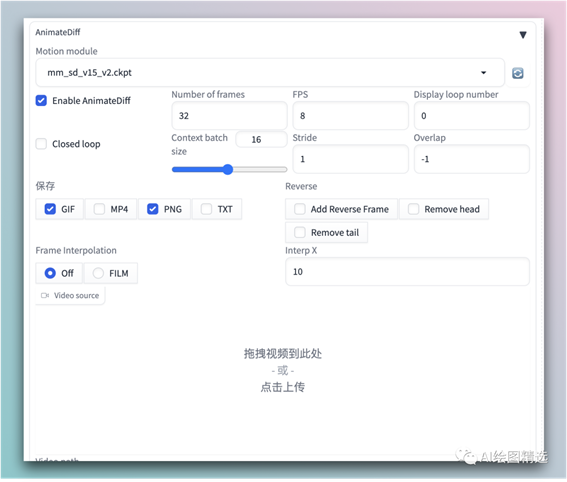
先介绍几个基础参数:
·Motion Module:AnimateDiff 使用的模型了,也就是前面下载的
·Enable AnimateDiff:启用
·FPS:每秒的帧数(每一帧一张图片)
·Number of frames:总帧数。总帧数/FPS = 视频的长度,上面的例子最后就会生成4秒钟的视频
第三步:生成视频
直接点击生成看看效果。
通过中间效果图来能看出来,一共生成了32张图(总帧数)
喝个咖啡☕️等待一会儿...

emmm.... 发现效果还是比较差的,连续性也一般般,虽然不会出现闪烁,不过这个画质、脸部细节太糟糕了。
下面接着做一些优化
四 细节优化
脸部细节优化
前面我们说了 AnimateDiff 支持结合其它插件一起使用,前面的文章我们讲过了使用
adetail 来解决崩脸问题,这我们可以直接开启使用
连续性优化
启用 AnimateDiff 的Frame Interpolation,将Frame Interpolation设置为 FILM,将Interp X设置为 FPS 的乘数。例如,将其设置为 5 会使 8 FPS 视频达到 40 FPS。
也可以启动反向帧Add Reverse Frame,相当于是把视频正着播放一遍,在反着播放一遍(实际上只会看着更加流畅了)
调整完再生成一次看看效果

效果是不是嘎嘎上来了。脸部细节、连续性都有提升。
只要你的GPU扛得住,也可以直接启用高清修复,让画面更加清晰!
拉大FPS让视频的连续性更好!
五 坑坑坑
提示词长度问题
 提示词的长度不能超过75。如果超过的话,那么最后的视频就会被切割然拼接。
提示词的长度不能超过75。如果超过的话,那么最后的视频就会被切割然拼接。
多次生成视频时报错
如果多次生成视频的时候出现下面的错误信息
Expected weight to be a vector of size equal to the number of channelsininput, but got weight of shape [1280] and input of shape [16, 2560, 9, 9]
那么你需要在启动SD的时候删除掉--xformers参数。
在留个坑,后面在填。目前只是基于文生生成最基础的视频,后面我们再结合 ControlNet 和原视频生成新视频以及视频换脸功能。
出自:https://mp.weixin.qq.com/s/baRRNS9_7aOGtuKqDKeYtw
一个可扩展、功能丰富且用户友好的自托管 WebUI,适用于各种 LLM 运行器,支持的 LLM 运行器包括 Ollama 和 OpenAI 兼容的 API。