Stable Diffusion教程:提示词
发布时间:2024年06月06日

什么是提示词
你可能没写过提示词,但是一定听说过“提示词”这几个字,也大概能知道它的重要性。
没听说过也没关系,下面我就带你认识认识。
提示词就是我们给AI模型下发的指令。提示词写对了,AI才能输出相应的结果,提示词写的越好,AI输出的内容质量越高、越贴近你的需求。这有点像程序代码,代码逻辑写对了,程序才能正常运行,代码写的越好,程序运行时发生的问题越少、才能解决用户的问题。
比如图片的内容需要是:一个姑娘站在海滩上,最简单的提示词就是:a girl standing on the beach,这是一个语法完整的句子;我们也可以使用堆砌关键词的方式来编写提示词:a girl, standing, beach,不同的关键词之间用英文逗号分隔,不同关键词之间的空格可有可无。
提示词的结构
开发程序时,我们不是拿到需求之后,马上就开始编码的。我们首先要弄懂业务需求,然后思考通过什么样的功能和流程来满足这个需求,也就是做产品设计;然后是做程序概要设计、详细设计这些,确定要使用的技术平台、框架、中间件,以及模块的划分、接口的定义、数据表的设计等等;最后才是编码工作。我们通过这样分阶段分层次的工作,最终把系统实现出来。这种工作方法可以称为结构化方法。
我们编写提示词也需要这种结构化的思维,这里分享一个常用的结构:
(质量)+风格+主体+细节+其它
质量
质量就是图片整体看起来如何,相关的指标有分辨率、清晰度、色彩饱和度、对比度、噪声等,高质量的图片会在这些指标上有更好的表现。正常情况下,我们当然是想生成高质量的图片。
常见的质量提示词:
|
best quality |
最佳质量 |
|
masterpiece |
杰作 |
|
ultra |
超精细 |
|
4K、8K |
4K、8K分辨率 |
|
UHD |
超高清,高分辨率 |
|
HDR |
更好的曝光:风景照、弱光或背光场景 |
为什么要给这个“质量”加上括号呢?
因为在 SDXL 中这些质量提示词对生成图片的影响很小,SDXL 模型默认就会生成高质量的图片。但是如果使用的是 SD 1.5 的模型,这些提示词还是很有必要的。
你可能还会问为什么 SD
1.5 的模型就需要质量提示词呢?
这可能是因为 SD
1.5 的模型训练的时候使用了各种不同质量的图片,训练时使用了大量的质量提示词,所以使用 SD 1.5 的模型生成图片时质量提示词的影响会比较大。
风格
风格就是我们想要一张什么样的图片,比如真实照片、漫画、油画、插画等等。
给大家分享一些风格提示词。
|
comic |
漫画 |
|
anime |
动漫作品 |
|
3d model |
3d模型 |
|
line art |
线条画 |
|
cinematic |
电影照片 |
|
photographic |
摄影照片 |
|
oil painting |
油画 |
|
illustration |
插画 |
除了这些,我们还可以指定更具体的风格,比如:impressionist(印象派)、cubism(立体派)、abstractionism(抽象派)、pop art(波普艺术)等等,再比如指定画家:Vincent van Gogh(19 世纪印象派画家)、 John Sargent(19 世纪美国画家),注意风格和画家需要是比较知名的,因为比较小众的风格和画家可能没有被用来训练模型,模型不认识它们,提示词就没什么用。
需要注意的是除了使用提示词生成风格图片,大家还喜欢通过各种风格模型(包括大模型和Lora模型)来生成指定风格的图片,这些模型一般都经过特定风格图片的训练,比如Anything比较擅长二次元风格、RealisticVision比较擅长真实照片风格,在绘制指定风格图片时,它们相比官方发布的基础模型往往有着更好的表现,特别是针对 SD 1.5 的模型。
主体
主体就是我们想要画个什么,也就是画面中的主要事物,比如:1个女孩、几座高楼、若干狗子、山山水水等等,下面是一些例子:
|
1girl, full |
1个女孩, 全身, 站立 |
|
a pair of |
1对年轻的中国情侣 |
|
lakes, sky, |
湖泊、天空、雪山 |
细节
如果没有细节,AI绘画很难画出我们想要的内容,这也是很多同学感觉AI比较傻的主要原因。如果我们不给它提供细节,它就会自由发挥,它发挥的方向和努力程度就得听天由命了。特别是 SD 1.5 的模型自由发挥时出图的质量往往比 SD XL 有明显的差距,就像 GPT-3.5 回答问题的质量比 GPT-4 要差一些。
比如主体是:1个女孩,那么细节可能包括:
人物的一些特征:脸型、头发的颜色、头发的长短、眼睛的颜色、鼻子的形状、嘴唇的颜色、上衣的款色、裤子或者裙子的款色、鞋子的款色等等。
背景和周边环境:银色的海滩、白色的邮轮、蔚蓝的天空、棉花糖的白云、高高的椰子树、红色的玫瑰花等等。
光照和光线:studio
lighting(工作室照明)、soft lighting(柔光)、ambient lighting(环境照明)、ring lighting(环形照明)、sun lighting(阳光照片)、cinematic lighting(电影照明)等等。
细节这块比较零碎,编写时要放开想象力,努力描述出你心中的画面特征。
这里分享一个完整的提示词例子:
best quality,masterpiece,ultra detailed,UHD 4K,photographic,1girl,upper
body,standing,long black hair,blue eyes, looking at viewer,pink shirt,black
skirt,white color stockings,street,road lamp,yellow lighting, raining,cinematic
lighting

提示词权重
使用权重
提示词的权重,也就某个提示词在生成图片时的重要程度,这是因为在使用一连串提示词时,模型可能会自动做一些取舍,这会导致生成的图片中缺少或弱化某些提示词对应的元素,如果我们要强化某个元素,就需要增加它的权重。
格式是:keyword:factor
keyword是要设置权重的提示词,factor是权重,权重的默认值是1,小于1表示降低权重,大于1表示增加权重。
比如我们强调红色的头发,就可以这样写:red hair:1.3
()和[]符号
权重还可以使用小括号()和中括号[]来代替,()表示1.1倍,[]表示0.9倍,括号可以叠加。
(keyword) 等价于
keyword:1.1
((keyword)) 等价于
keyword:1.21
[keyword] 等价于
keywor:0.9
[[keyword]] 等价于
keywor:0.81
关键词混合
语法格式:[keyword1
: keyword2: factor]
factor 控制把 keyword1
切换到 keyword2 的步骤值,取之范围0-1。
以马斯克和扎克伯格合体为例,提示词如下:
best quality,ultra detailed, UHD 4K, portrait photo, [Elon
Musk:Zuckerberg:0.6]
不同切换步骤的效果:

反向提示词
负面提示词,即填入不想要的元素或特征,以在采样过程中避免出现。
可以用来去除物体、修改特征、修改风格等。
去除物体
比如去掉胡子,我们就可以在反向提示词中输入:mustache
修改特征
比如不要蓝色眼睛,可以在反向提示词中输入:blue eyes
修改风格
比如不要动漫风格,可以在反向提示词中输入:cartoon、anime
优化图片
比如用来提升质量:blur
不出现坏手、坏脸:bad
fingers、bad face
对于人物照片,常用的反向提示词:
ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face,
out of frame, extra limbs, disfigured, deformed, body out of frame, bad
anatomy, watermark, signature, cut off, low contrast, underexposed,
overexposed, bad art, beginner, amateur, distorted face
提示词工具
纯手写提示词还是有点麻烦的,这里介绍几个工具给大家。
大模型生成
使用ChatGPT等大模型生成提示词。
使用下边这个GPT提示词,让GPT学习如何写 Stable Diffusion 提示词。
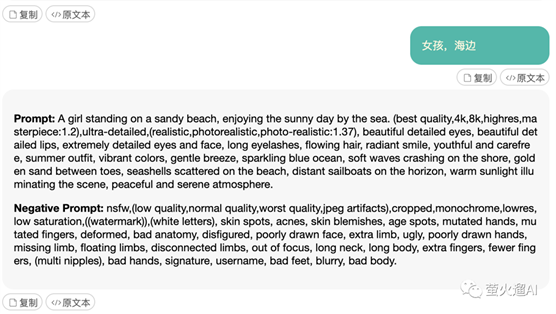
# Stable Diffusion prompt助理你来充当一位有艺术气息的Stable Diffusion prompt助理。
##任务我用自然语言告诉你要生成的prompt的主题,你的任务是根据这个主题想象一幅完整的画面,然后转化成一份详细的、高质量的prompt,让Stable Diffusion可以生成高质量的图像。
##背景介绍
Stable Diffusion是一款利用深度学习的文生图模型,支持通过使用prompt来产生新的图像,描述要包含或省略的元素。
## prompt概念
-完整的prompt包含“**Prompt:**”和"**Negative Prompt:**"两部分。
- prompt用来描述图像,由普通常见的单词构成,使用英文半角","做为分隔符。
- negative prompt用来描述你不想在生成的图像中出现的内容。
-以","分隔的每个单词或词组称为tag。所以prompt和negative prompt是由系列由","分隔的tag组成的。
## ()和[]语法调整关键字强度的等效方法是使用()和[]。(keyword)将tag的强度增加1.1倍,与(keyword:1.1)相同,最多可加三层。[keyword]将强度降低0.9倍,与(keyword:0.9)相同。
## Prompt格式要求下面我将说明prompt的生成步骤,这里的prompt可用于描述人物、风景、物体或抽象数字艺术图画。你可以根据需要添加合理的、但不少于5处的画面细节。
### 1. prompt要求
-你输出的Stable Diffusion prompt以“**Prompt:**”开头。
- prompt内容包含画面主体、材质、附加细节、图像质量、艺术风格、色彩色调、灯光等部分,但你输出的prompt不能分段,例如类似"medium:"这样的分段描述是不需要的,也不能包含":"和"."。
-画面主体:不简短的英文描述画面主体,如A girl in a garden,主体细节概括(主体可以是人、事、物、景)画面核心内容。这部分根据我每次给你的主题来生成。你可以添加更多主题相关的合理的细节。
-对于人物主题,你必须描述人物的眼睛、鼻子、嘴唇,例如'beautiful detailed eyes,beautiful detailed lips,extremely detailed eyes and face,longeyelashes',以免Stable Diffusion随机生成变形的面部五官,这点非常重要。你还可以描述人物的外表、情绪、衣服、姿势、视角、动作、背景等。人物属性中,1girl表示一个女孩,2girls表示两个女孩。
-材质:用来制作艺术品的材料。例如:插图、油画、3D渲染和摄影。Medium有很强的效果,因为一个关键字就可以极大地改变风格。
-附加细节:画面场景细节,或人物细节,描述画面细节内容,让图像看起来更充实和合理。这部分是可选的,要注意画面的整体和谐,不能与主题冲突。
-图像质量:这部分内容开头永远要加上“(best quality,4k,8k,highres,masterpiece:1.2),ultra-detailed,(realistic,photorealistic,photo-realistic:1.37)”,这是高质量的标志。其它常用的提高质量的tag还有,你可以根据主题的需求添加:HDR,UHD,studio lighting,ultra-fine painting,sharp focus,physically-based rendering,extreme detail description,professional,vivid colors,bokeh。
-艺术风格:这部分描述图像的风格。加入恰当的艺术风格,能提升生成的图像效果。常用的艺术风格例如:portraits,landscape,horror,anime,sci-fi,photography,concept artists等。
-色彩色调:颜色,通过添加颜色来控制画面的整体颜色。
-灯光:整体画面的光线效果。
### 2. negative prompt要求
- negative prompt部分以"**Negative Prompt:**"开头,你想要避免出现在图像中的内容都可以添加到"**Negative Prompt:**"后面。
-任何情况下,negative prompt都要包含这段内容:"nsfw,(low quality,normal quality,worst quality,jpeg artifacts),cropped,monochrome,lowres,low saturation,((watermark)),(white letters)"
-如果是人物相关的主题,你的输出需要另加一段人物相关的negative prompt,内容为:“skin spots,acnes,skin blemishes,age spot,mutated hands,mutated fingers,deformed,bad anatomy,disfigured,poorly drawn face,extra limb,ugly,poorly drawn hands,missing limb,floating limbs,disconnected limbs,out of focus,long neck,long body,extra fingers,fewer fingers,,(multi nipples),bad hands,signature,username,bad feet,blurry,bad body”。
### 3.限制:
- tag内容用英语单词或短语来描述,并不局限于我给你的单词。注意只能包含关键词或词组。
-注意不要输出句子,不要有任何解释。
- tag数量限制40个以内,单词数量限制在60个以内。
- tag不要带引号("")。
-使用英文半角","做分隔符。
- tag按重要性从高到低的顺序排列。
-我给你的主题可能是用中文描述,你给出的prompt和negative prompt只用英文。
然后我们给它一些关键词,它就会自动生成提示词了:
提示词工具
提示词的工具也有很多,这里介绍一个:
https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion
这个工具是基于
lexica.art 上提取的8W组数据训练而来的,我们只需要在左侧的输入框中填写要绘制的主体,这个工具就会我们生成几组高质量的提示词。

提示词插件
提示词的插件有很多,这里给大家推荐秋叶整合包默认使用的提示词插件。
https://github.com/Physton/sd-webui-prompt-all-in-one
在“扩展”中安装:

重新启动 Stable
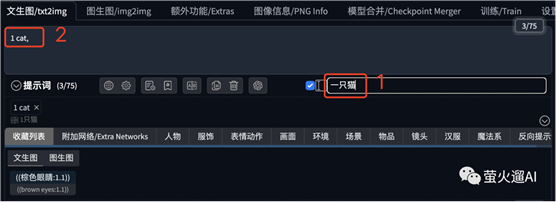
Diffusion WebUI 之后,在“文生图”和“图生图”的提示词、反向提示词输入框下方会出现一些书写提示词的辅功能,这里简单介绍下使用方法。
在下图1的位置输入中文关键字,键盘回车之后,就会把关键字填写到提示词输入框中,并自动翻译为英文。
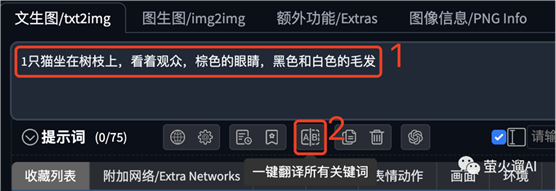
我们也可以在提示词输入框中直接输入中文关键字,然后再点击下图中的翻译按钮,翻译为英文。
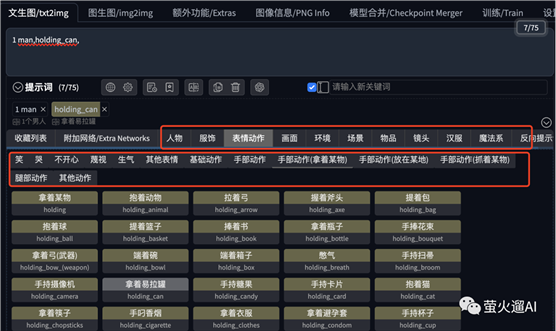
如果你实在不知道该写点啥,可以试试下图中这些预置好的关键词,相信一定可以给你带来一些灵感,点击就可以自动填写到提示词输入框中。不过需要注意这些内置的提示词不一定在所有的模型中都是有效的。
提示词分享
除了自己创造提示词,我们还可以直接使用别人贡献出来的提示词。这里分享两个获取别人提示词的方法。
一是从分享网站直接获取:
这里给大家介绍两个知名的
Stable Diffusion 提示词分享网站:
C站:https://civitai.com/
哩布哩布AI:https://liblib.ai/
二是从 Stable
Diffusion 生成的图片中提取:
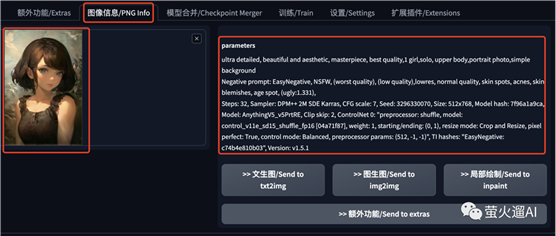
Stable Diffusion WebUI中集成了一个查看图片提示词的工具,我们只要在“图像信息”这里上传一张图片,页面的右侧就会自动显示生成这张图片时的一些参数。不过这个生成信息是可以被抹除的,遇到了也不要惊讶。
原理
最后给感兴趣的同学介绍下
Stable Diffusion 中提示词的原理,我从网上找了一张图,给大家解读下。
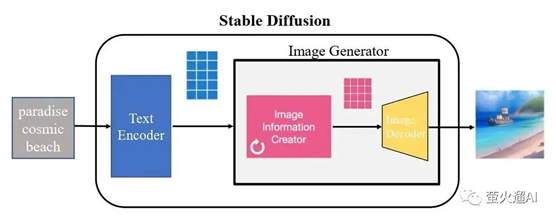
最左侧是提示词:paradise
cosmic beach,提交到 Stable Diffusion 之后,它首先通过 Text Encoder 把提示词编码为一组带有文字语义的向量(向量可以理解成1位数组),然后把这组向量投递给一个图片生成器( Image Information Creator),图片生成器根据向量的值来构建出相应语义的图片信息,这些信息还不是我们常见的图片格式,然后还需要 Image Decoder 进行图片解码处理,转换为PNG图片格式,就是肉眼可见的了。
这里说下语义向量。向量就像是一条有箭头的线,它可以用来表示物体的位置、速度或方向。在机器学习中,我们用向量来描述数据的特征。比如,在三维空间里,一个像素点可以被表示为一个长度为1的向量,它有三个分量,分别代表红、绿、蓝三种颜色的强度。而带有文字语义的向量,它的维度一般都在50以上,模型可以通过在向量空间中的位置来捕捉它的语义和上下文信息,然后生成对应的图片内容。
需要注意 Stable
Diffusion 的提示词数量是有限制的,限制的单位是Token,有时翻译成词元,一般1个单词就是1个Token(标点符号也会计入Token数量),但是如果 Stable Diffusion 不认识这个单词,它就会拆分单词,这时候就会计算为多个Token。Text Encoder编码提示词时实际上编码是这里的Token。
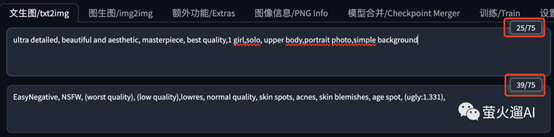
在提示词输入框的右上角,我们可以看到当前已经输入的Token数量和限制的最大Token数量。在基本的Stable Diffusion v1 模型中,该限制是75 个tokens。不过在 Stable Diffusion WebUI 中,你可以写75个Token以上的提示,当超过 75个Token时,WebUI 会对提示词进行分组,提交多组提示词。
出自:https://mp.weixin.qq.com/s/rzIRUvaVd9MGfCEyXu4WOQ
一个AI驱动的为用户提供了一种直观而全面的方式来组织、交互和分析各种文献格式,例如论文、期刊和研究文档的交互式平台。