HAI-Chat:高效且轻量的一键式 RLHF 训练工具
发布时间:2024年06月06日
对话式人工智能工具的流行引发了人们对人工智能安全的担忧。构建有益、真实和无害行为的
LLMs,目前首选方案是基于人类反馈的强化学习(RLHF)。其中 ChatGPT 采用 RLHF 最先取得了显著的效果。
众所周知,RLHF 三阶段分别是:有监督微调(SFT),奖励模型(RM)与近端策略优化(PPO)。前两个步骤是基于特定的数据训练准备模型,属于人类反馈(HF)的部分;而 PPO 则是 OpenAI 提出的强化学习算法(RL),基于前两步构建的准备模型再训练提升主干网络。
幻方x深度求索在萤火智算集群上进行大量的 RLHF 训练实践,研发优化了一套轻量的 PPO 训练工具,名叫 HAI-Chat。它适配萤火智算集群的特性,更兼容HAI-LLM 大模型训练框架训练出来的模型,相比开源 RLHF 方案提速12倍。本文将为大家详细介绍。
RLHF 概述
回顾之前文章《LLaMA-2 技术详解(一):数据打标》中所展示的 LLaMA-2 训练流程:
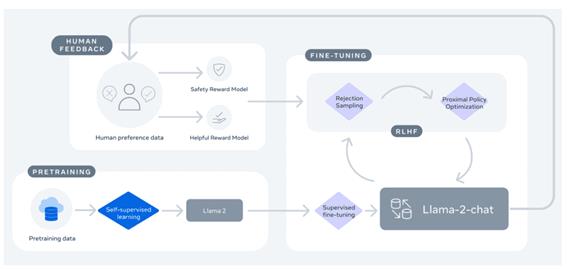
人反馈打标构建的数据信息通过 SFT,RM 与 PPO 逐步融入到主干模型中。
步骤一:有监督微调
有监督微调(Supervised Fine-Tuning,简称 SFT),又被称为行为克隆(Behavioral Cloning,简称 BC),是 RLHF 训练过程中的一个重要步骤。在这个步骤中,预训练好的模型使用专家行为数据来进行微调训练,其旨在让模型的输出尽可能地复制或模仿专家的行为。这里不尝试优化某种奖励函数,因此它可能无法处理那些专家数据中没有覆盖到的情况,因为它完全依赖于专家的行为数据。
步骤二:奖励模型
奖励模型(Reward Model,简称 RM)是 RLHF 训练过程的第二阶段,它的目标是训练一个模型来适应人类的偏好。在这个阶段,首先从提示库中进行采样,并使用 LLM 生成多个响应。然后人工对这些响应进行排名,根据这些排名训练一个奖励模型。奖励模型的目标是学习人类对于不同响应的偏好,并将这些偏好编码到模型中。如下图所示:
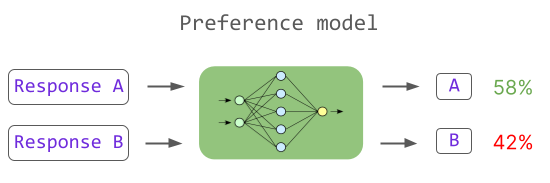
这样,奖励模型可以用来为后续模型生成的新响应打分,从而在后续的训练中引导模型生成更符合人类偏好的内容。这种方式不仅能帮助模型处理训练数据中未覆盖的情况,也能减少模型生成不确定或模棱两可的回答,从而打破 SFT 行为克隆的影响。
在萤火智算集群中可以执行如下命令训练 RM:
·
hfai python train_reward.py --config hai_chat/configs/deepseek_rm_13b.py -- -n 8 -p 30
步骤三:近端策略优化
近端策略优化(Proximal Policy Optimization,简称 PPO)是一种强化学习算法,它通过引入奖励信号来调整模型的行为,使模型生成的内容更符合人类的偏好。具体来说,PPO 通过最大化预期奖励来调整模型的策略,使模型在选择行为时更倾向于选择可以得到更高奖励的行为。如下图所示:
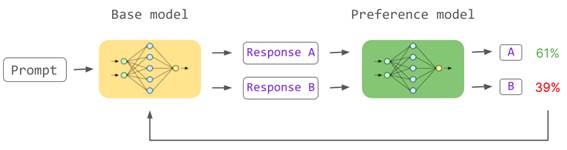
在这个阶段中,我们首先使用 SFT 微调的模型和奖励模型来生成一个初始的策略。然后,我们使用 PPO 算法来调整这个策略,使模型在生成内容时更考虑人类的偏好。通过这个阶段的训练,模型不仅可以理解人类的语言,还可以理解人类的偏好,并生成更符合人类偏好的内容。
在萤火智算集群中可以执行如下命令进行 PPO 训练:
·
hfai python train_rlhf.py --config hai_chat/configs/deepseek_rlhf.py -- -n 2 -p 30
下面将为大家介绍 HAI-Chat 中 PPO 的实现。
近端策略优化(PPO)
具体来说,近端策略优化(PPO)可以分为三个阶段:
1.Rollout
and Evaluation:在这个阶段,我们从 Prompt 库里抽样,使用语言模型生成文本,然后使用奖励模型(RM)给出奖励得分。这个得分反映了生成的文本的质量,比如它是否符合人类的偏好,是否符合任务的要求等。
2.Make
Experience:在这个阶段,我们收集了一系列的“经验”,即模型的行为和对应的奖励。分为三步:旧策略采样(Old Policy Sampling),KL
散度惩罚(KL Penalty)与生成优势估计(Generalized Advantage Estimation,简称 GAE)。通过这三步,保证经过强化学习后的模型不会过于偏离原始预训练模型,提高整体的训练稳定性。
3.Optimization:这个阶段是 PPO 算法的关键阶段,包含五个步骤:新策略采样(New Policy Sampling),Critic
Loss,Actor Loss,Entropy Loss 和策略度量(PolicyKL)。在这个阶段,我们使用收集到的经验来更新模型的参数。具体来说,训练优化产生的新策略不断更新 Critic 和
Actor,加入熵和策略度量保证策略的多样性和训练稳定。
利用 HAI-Chat 自定义 PPO 的训练
HAI-Chat 提供了简单易用的接口,用户只需设置自定义的 tokenizer 和 RLHF 训练配置(cfg),即可构建自己的 PPO 策略进行训练。示例代码如下:
1 from hai_chat.tokenizers.llama_tokenizer import LineBBPETokenizerForRLHF
2 from hai_chat.algorithms.ppo import PPO
3
4 tokenizer = LineBBPETokenizerForRLHF.get_tokenizer()
5
6 # 根据 cfg 构建 actor 与 critic 模型与 dataloader
7 trainer = PPO(
8 tokenizer=tokenizer,
9 cfg=rlhf_cfg
10 )
11
12 # 加载模型
13 trainer.load_ckpt()
14
15 # 开始训练
16withtrainer.cm.start_save_thread(save_interval=rlhf_cfg.save_every_steps):
17 for epoch in rlhf_cfg.epochs:
18 trainer.set_epoch(epoch)
19 trainer.train()
RLHF 训练配置(rlhf_cfg)示例如下:


这里 train() 函数里的执行逻辑是:

训练效果
对比目前最新的的 RLHF 开源训练框架,Safe-RLHF,HAI-Chat 在相同配置下,相比 Safe-RLHF 速度提升了12倍。具体测试结果如下:
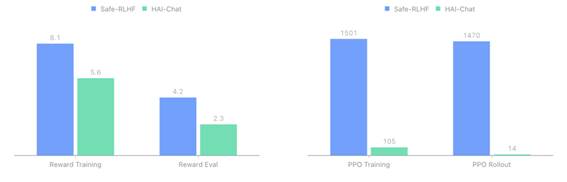
上图左侧展示了奖励模型每 Epoch 的训练与评估耗时,上图右侧展示了 PPO 每 Epoch 的训练和 Rollout 耗时。可以看到,相比于 Safe-RLHF,HAI-Chat 可以加速奖励模型 30%~50%,而对于 PPO 训练的加速则更加明显,可以达到10倍以上的加速。对于一个 7B 大小的模型在双机16张 A100 上执行,Safe-RLHF 完整训练完成需要耗时 36 小时,而 HAI-Chat 只需 3 小时即可完成。HAI-Chat 可以大幅提高模型调优的速度,降低成本。
总结
本文简要介绍了 RLHF 的技术原理和 HAI-LLM 框架中 PPO 算法的实现。在大语言模型发展与商业化的道路中,RLHF 作为提升 LLMs 有益性和安全性的关键技术之一,将面对大量场景的挑战。我们将持续关注相关技术的改进与发展。
出自:https://mp.weixin.qq.com/s/v93EkKl9nDWoPR9-cRtdLA
一款功能强大的AI声音和歌曲生成器工具,允许用户使用来自著名主播、政治家、歌手、卡通人物等的数千种声音生成 AI 翻唱。