解读wav2lip:探究语音驱动唇部动作的技术原理!
发布时间:2024年06月06日
本文将深入介绍一下wav2lip的技术原理和细节,了解它是如何实现语音驱动唇部运动的!

本文来自ACM 2020:A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild
代码开源:https://github.com/Rudrabha/Wav2Lip
一、现有方法不足
常见的语音驱动嘴唇运动方法在处理动态的和无约束的说话人脸视频时,通常无法准确地合成口型,导致生成的视频与音频不同步,主要原因包括两方面:
(1)传统的基于像素的人脸重建损失无法准约束音频-口型同步:因为面部重建损失是基于整个图像计算的,而唇部区域只占整个图像的很小一部分(不到4%),因而无法聚焦唇部细节。此外,在人脸重建的训练过程中,只有在训练的中后期才开始优化口型,导致前期监督信息缺乏。
(2)传统的基于GAN的判别器在音频-口型同步检测方面准确率较低:传统的GAN判别器只使用单帧图像来评估口型同步,缺乏时间上下文信息,无法评估口型动态变化质量。而且由于生成过程中存在伪影,GAN判别器更容易关注视觉伪影,从而忽略音频和口型的对应关系。
为了解决上述两个问题,wav2lip引入了一个在真实视频中预训练的专家口型同步判别器,且包含多帧信息,用于判断音频和口型是否同步。实验发现,相较于基于像素的人脸重建方法,这个专家判别器在口型同步判别任务上更精准。在训练阶段,将该专家判别器保持冻结状态,保证判断结果不受伪影的干扰。
二、 本文方法介绍
wav2lip模型的训练分为两个阶段,第一阶段是专家音频和口型同步判别器预训练;第二阶段是GAN网络训练。训练部分包括一个生成器和两个判别器,这里的两个判别器分别是专家音频和口型同步判别器和视觉质量判别器,前者预训练完毕后,在GAN训练过程中保持冻结。
具体来说,wav2lip的训练流程如下:首先,提取音频特征,将音频特征与人脸图像进行配对,形成一个音频-图像对,然后训练专家音频和口型同步判别器。接下来,wav2lip使用GAN来学习音频-图像对之间的映射关系。生成器网络负责生成逼真的嘴唇动作,而判别器网络则负责评估生成的嘴唇动作的一致性和真实性,通过不断的训练和反馈,生成器网络逐渐学习到如何根据音频特征生成与之匹配的嘴唇动作。
在训练完成后,wav2lip模型根据音频信息逐帧生成一个说话的人脸视频。

Fig.1 wav2lip architecture
2.1 数据集处理
本文使用的LRS2数据集,来自BBC的唇语视频,包含4万多个口语句子,它的训练集、验证集和测试集是根据广播日期进行划分。用户也可以自行收集各种视频数据,提升目标场景的效果。
推荐使用视频帧率为25fps,音频采样率为16k,视频的一帧对应音频块的长度为16。
2.2 专家音频和口型同步判别器预训练
wav2lip专家音频和口型同步判别器用于评估生成的唇部动作与音频的同步性,它是由syncNet改进而来,关于syncNet只需要简单了解一下:
syncNet包含一个人脸编码器和一个音频编码器,两者都由一系列2D卷积层组成。人脸编码器的输入是一个大小为 �� 的视频窗口 � ,包含连续的人脸帧,但这些帧仅保留人脸下半部分。音频编码器的输入是一个大小为 ��×� 的语音片段 � ,其中 �� 和 �� 分别是视频和音频的时间步长。syncNet的两个 编码器分别计算音频嵌入和视频嵌入,然后使用最大间隔损失进行训练,最小化匹配的音频-口型对之间的嵌入距离。最大间隔损失的原理是基于最大间隔分类器的思想,通过最大化类别之间的间隔来提高分类器的鲁棒性和泛化能力。
wav2lip对SyncNet 进行了三个方面的修改,训练了更好的专家口型同步判别器:即使用RGB图像作为输入,增加模型的深度,使用余弦相似度二元交叉熵损失,即余弦相似度BCE损失。
wav2lip使用LRS2训练集对判别器进行训练,在训练过程中,每个样本的时间维度设置为5帧(Tv = 5),按通道维度拼接起来,这样能够获取视频帧的上下文信息。在测试集上评估,wav2lip的专家判别器的准确率达到了91%,而LipGAN中使用的判别器的准确率只有56%。
有了准确的口型同步判别器后,可以在训练过程中利用它来对生成器进行优化,提高生成器生成口型的准确性。
2.3 口型生成器
wav2lip的生成器负责生成包含目标口型的人脸图像,是一个2D-CNN编码器-解码器结构,包含三个由卷积网络组成的模块:Identity Encoder,Speech Encoder,Face Decoder。
其中,Identity Encoder用于编码身份特征,把随机参考帧与姿势先验帧按通道维度拼接起来作为输入。参考帧包含目标人脸的完整外观特征,如嘴唇的形状、颜色和纹理等,用于唇部形状和运动的合成。姿势先验帧的下半部分被掩蔽,但提供了目标人脸的姿势信息,比如头部和脸部的方向和角度等信息,确保合成的唇部动作与目标人脸的姿势一致。同时,姿势先验帧也作为重建目标。这两个图像共同作为输入,确保生成的人脸的外观、口型和姿态更加准确。
Speech Encoder 用于编码输入的语音片段,Face Decoder则通过反卷积进行上采样,用于重建人脸图像,它的输入是编码后的音频特征和身份特征的拼接。
生成器通过最小化生成帧与真实帧之间的L1重构损失来提高生成的帧的质量,重建目标函数为:
![]()
wav2lip生成器独立地生成每一帧,然后将连续生成的帧序列输入给预训练的专家音频和口型同步判别器。
具体来说,为了在训练过程中与专家判别器的配合,生成器需要生成 tv=5 个连续帧,但只使用生成的人脸的下半部分进行判别,生成器通过最小化来自专家判别器的同步损失来提高生成的帧的口型同步质量,同步损失函数为余弦相似度二元交叉熵损失:
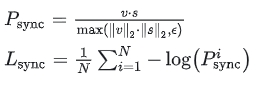
在生成器的训练过程中,专家判别器的权重保持不变,因为专家判别器是从真实视频中的口型数据训练的,无需改变。通过这种生成器的结构和专家判别器的共同作用,可以生成任意人脸对象,并且口型与语音的同步性较好。但由于LRS2清晰度偏低,生成图像脸部较模糊,而且牙齿部分还原度稍差,可以选择清晰度更高的数据集,或者利用超分模型提升脸部的清晰度。此外,当参考人脸图片侧脸时,脸部可能会不协调。
2.4 视觉质量判别器
实验观察到,使用专家口型同步判别器可以使生成器生成准确的口型形状,但有时候会导致生成区域出现模糊或者伪影。为了提高生成图像质量,wav2lip在生成器中使用了一个额外的的视觉质量判别器。
具体来讲,wav2lip有两个判别器,口型同步判别器和质量判别器,一个用于提高口型同步准确性,另一个用于提高生成图像视觉质量。口型同步判别器在GAN训练期间保持冻结,视觉质量判别器只对生成的人脸的质量进行监督,不负责口型同步。
视觉质量判别器 D 由多个卷积块组成,训练目标是最大化目标函数 L disc:

2.5 生成器训练
生成器的最终优化目标是重建损失、同步损失和对抗损失的加权和,用公式表示如下:

重建损失衡量生成器生成的图像与原始图像之间的差异,同步损失衡量生成口型与目标口型之间的差异,对抗损失衡量生成的图像在对抗训练中与判别器的对抗表现。通过最小化这些损失函数的加权和,生成器可以生成口型同步的高质量人脸图像。
三、参考文献
· LipGAN:Towards Automatic Face-to-Face Translation
· SyncGAN: Using learnable class specific priors to generate synthetic data for improving classifier performance on cytological images
最新版本的 GPT-4,没有附加功能