AI绘画巅峰对决:Stable Diffusion 3与DALL·E 3原理深度比较
发布时间:2024年06月06日
 https://stability.ai/news/stable-diffusion-3
https://stability.ai/news/stable-diffusion-3
最近,Stable Diffusion 3 的预览版已经亮相啦!
虽然这个AI绘画模型还没全面上线,但官方已经开启预览申请通道了。
https://stability.ai/stablediffusion3
而且好消息是,后面还会推出开源版本哦!
这个模型套件真的很强大,参数范围从800M到8B,选择多多,无论你有什么创意需求,它都能满足你。
Stability AI 分享打造 Stable Diffusion 3 的两大核心技术:Diffusion Transformer 和 Flow Matching。
这两项技术到底有什么奥妙呢?
还有Stable Diffusion 3 和 DALL·E 3 相比,原理上有什么不同呢?
我们也来一起剖析剖析。
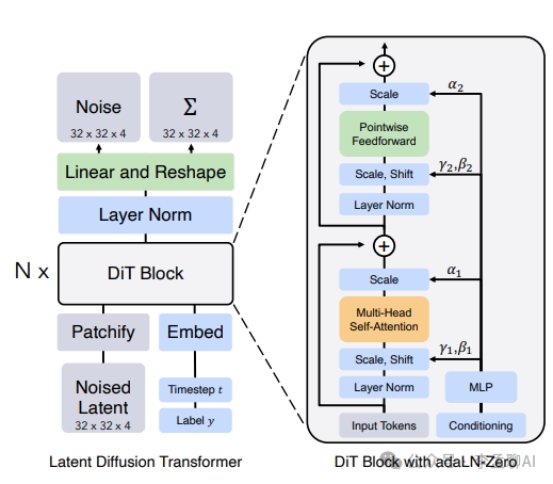
Stable Diffusion 3 中 Diffusion Transformer
 https://arxiv.org/abs/2212.09748
https://arxiv.org/abs/2212.09748
篇幅有限,我简要回顾下U-Net架构。
在原始的 U-Net 基础上,插入了交叉注意力模块,巧妙地引入了我们输入的 prompt 文本描述信息,从而帮助我们随心所欲地控制 AI 绘画的内容。
U-Net 在扩散模型中被用于预测噪声。
AI 绘画中用到的 U-Net 实际上是引入了 Transformer 思想的加强版 U-Net 模型。
Latent Diffusion Transformer(DiTs) 换掉扩散模型中的 U-Net 结构。
使用纯粹Transformer结构。
Transformer 结构的输入和输出“分辨率”可以做到相同,并且天生自带交叉注意力机制。
基于 Transformer 的扩散先验并不是预测每一步的噪声值,而是直接预测每一步去噪后的图像表征。
这种方式会提升生图性能和效率!
DALL-E 2 版本就已经使用类似架构。
论文:https://arxiv.org/abs/2212.09748
Stable Diffusion 3 中 Flow Matching
Flow Matching是一个新的生成模型框架,它让训练连续正态化流(CNF)变得更简单。
这个框架不依赖复杂的模拟或对数似然估计,而是直接处理生成目标概率路径的向量场。
简单来说,Flow Matching给我们提供了一张地图(向量场)和一条路线(概率路径),让我们能够更清晰地了解数据是如何生成的。
通过这张地图和路线,我们可以更轻松地训练生成模型,让它学习从噪声中生成出我们想要的数据。
Flow Matching还提出了一个叫做条件Flow Matching (CFM)的损失函数,这个函数让模型的训练变得更容易。
同时,它还支持各种概率路径,包括diffusion路径和OT路径,这让我们在训练模型时有了更多的选择。
论文:https://arxiv.org/abs/2210.02747
技术原理比较
DALL-E 3 在方法上进行了大量的创新和改进。
它摒弃了 unCLIP 的模型设计思路,转而汲取了 Imagen、Stable Diffusion 等AI模型的精髓,打造出了新一代的“技术融合体”。
DALL-E 3 用Dataset Recaptioning技术,重新生成图像标题,这些训练语料都是由GPT-4 Vision生成的。
简单来说,使用 ChatGPT 对用户提供的 prompt 扩写,也是为了让 DALL-E 3 的输入 prompt 更加贴近训练数据范式,避免模型出现“翻车”的现象。
Stable Diffusion 3 用的Flow Matching 提高生成效率。
提示:a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words "stable diffusion"

DALL-E 3
Stable Diffusion 3
说起来挺有意思的,DALL-E 3不再沿用上一代的 unCLIP 方案,反而搞起了新花样,引入了 VAE 结构,玩起了类似 Stable Diffusion 的那一套。
不仅如此,DALL-E 3 还特地加入了一个扩散模型解码器,就放在 U-Net 去噪后的潜在表示和 VAE 解码器之间。
不过呢,Stable Diffusion 3 这边倒是反其道而行之,居然要去除 U-Net 结构。
结语
通过比较发现AI模型就是互相学习过程。
AI模型好坏主要取决于三大要素:
1. 优秀的基础大语言模型。
2. 优质的训练素材。
3. 与任务匹配的合适算法和经过反复调优的超参数。
出自:https://mp.weixin.qq.com/s/WDUk1XQ4mzMutKdsHD2vcw
一个创新的人工智能体框架,CrewAI将尖端工具的优势与其自身独特的增强功能相结合,使用户能够轻松创建复杂而强大的自动化AI智能体。