评论能力强于GPT-4,上交开源13B评估大模型Auto-J
发布时间:2024年06月06日
随着生成式人工智能技术的快速发展,确保大模型与人类价值(意图)对齐(Alignment)已经成为行业的重要挑战。
虽然模型的对齐至关重要,但目前的评估方法往往存在局限性,这也让开发者往往困惑:大模型对齐程度如何?这不仅制约了对齐技术的进一步发展,也引发了公众对技术可靠性的担忧。
为此,上海交通大学生成式人工智能实验室迅速响应,推出了一款全新的价值对齐评估工具:Auto-J,旨在为行业和公众提供更加透明、准确的模型价值对齐评估。

· 论文地址:https://arxiv.org/abs/2310.05470
· 项目地址:https://gair-nlp.github.io/auto-j/
· 代码地址:https://github.com/GAIR-NLP/auto-j
目前,该项目开源了大量资源,包括:
· Auto-J 的 130 亿参数模型(使用方法,训练和测试数据也已经在 GitHub 上给出);
· 所涉及问询场景的定义文件;
· 每个场景手工构建的参考评估准则;
· 能够自动识别用户问询所属场景的分类器等。
该评估器有如下优势:
1. 功能使用方面
· 支持 50 + 种不同的真实场景的用户问询(query)(如常见的广告创作,起草邮件,作文润色,代码生成等)能够评估各类大模型在广泛场景下的对齐表现;
· 它能够无缝切换两种最常见的评估范式 —— 成对回复比较和单回复评估;并且可以 “一器多用”,既可以做对齐评估也可以做 “奖励函数”(Reward Model) 对模型性能进一步优化;
· 同时,它也能够输出详细,结构化且易读的自然语言评论来支持其评估结果,使其更具可解释性与可靠性,并且便于开发者参与评估过程,迅速发现价值对齐过程中存在的问题。
2. 性能开销方面
· 在性能和效率上,Auto-J 的评估效果仅次于 GPT-4 而显著优于包括 ChatGPT 在内的众多开源或闭源模型,并且在高效的 vllm 推理框架下能每分钟评估超过 100 个样本。
· 在开销上,由于其仅包含 130 亿参数,Auto-J 能直接在 32G 的 V100 上进行推理,而经过量化压缩更是将能在如 3090 这样的消费级显卡上部署使用,从而极大降低了 LLM 的评估成本 (目前主流的解决方法是利用闭源大模型(如 GPT-4)进行评估,但这种通过调用 API 的评估方式则需要消耗大量的时间和金钱成本。)
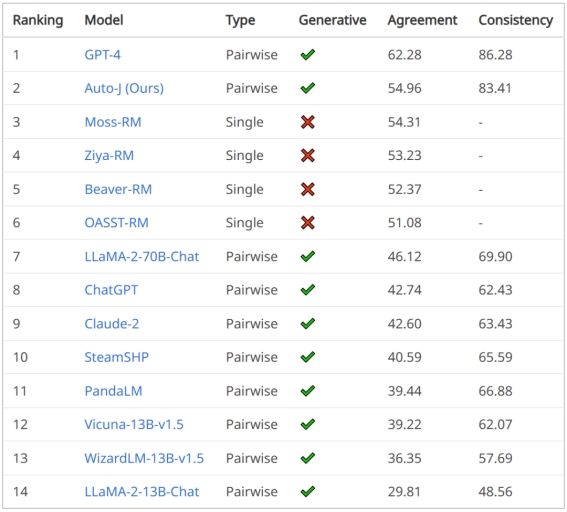
成对回复比较的排行榜结果
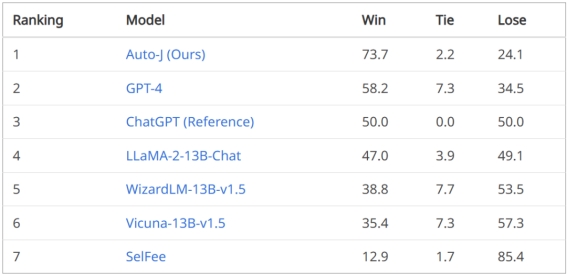
评论生成任务的排行榜结果
示例
注:本节提供的示例已由原始英文文本翻译为中文
下图例 1 为成对回复比较,红色字体高亮了显著区分两条回复的内容,并且用绿色字体高亮了 Auto-J 给出的评判中与用户偏好对齐的部分。

下图例 2 为单回复评估,绿色字体高亮了 Auto-J 给出的评判中切中要点的部分。

具体方法
训练数据总体上遵循如下的流程示意图:
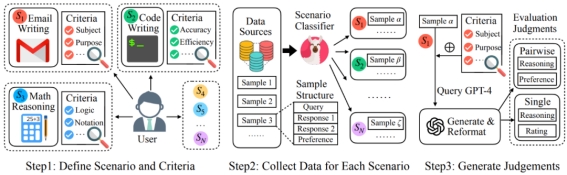
图1:训练数据收集流程示意图
场景的定义和参考评估标准:
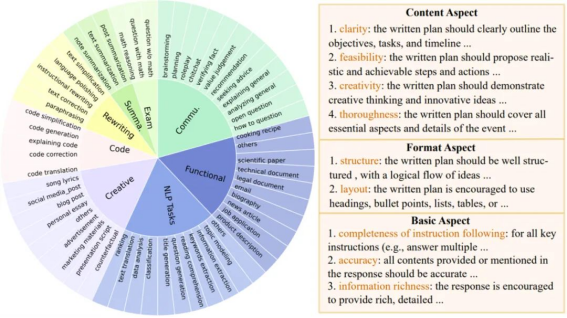
图 2:场景定义与参考评估标准
为了更广泛的支持不同的评估场景,Auto-J 定义了 58 种不同的场景,分属于 8 大类(摘要,重写,代码,创作,考题,一般交流,功能性写作以及其他 NLP 任务)。
对于每个场景,研究者手动编写了一套用作参考的评估标准(criteria),覆盖了这类场景下常见的评估角度,其中每条标准包含了名称和文本描述。评估标准的构建遵循一个两层的树状结构:先定义了若干组通用基础标准(如文本与代码的一般标准),而每个场景的具体标准则继承了一个或多个基础标准,并额外添加了更多的定制化标准。以上图的 “规划”(planning)场景为例,针对这一场景的标准包括了该场景特定的内容与格式标准,以及继承而来的基础标准。
收集来自多种场景的用户问询和不同模型的回复:
Auto-J 被定位成能够在定义的多种广泛场景上均表现良好,因此一个重要的部分就是收集不同场景下相应的数据。为此,研究者手动标注了一定量用户问询的场景类别,并以此训练了一个分类器用以识别任意问询的所属场景。在该分类器的帮助下,成功从包含了大量真实用户问询和不同的模型回复的若干数据集中(如 Chatbot Arena Conversations 数据集)通过降采样的方式筛选出了类别更加均衡的 3436 个成对样本和 960 个单回复样本作为训练数据的输入部分,其中成对样本包含了一个问询,两个不同的针对该问询的回复,以及人类标注的偏好标签(哪个回复更好或平局);而单回复样本则只包含了一个问询和一个回复。
收集高质量的评判(judgment):
除了问询和回复,更重要是收集作为训练数据输出部分的高质量评估文本,即 “评判”(judgment)。研究者定义一条完整的评判包含了中间的推理过程和最后的评估结果。对于成对回复比较而言,其中间推理过程为识别并对比两条回复之间的关键不同之处,评估结果是选出两条回复中更好的一个(或平局);而对于单回复样本,其中间推理过程是针对其不足之处的评论(critique),评估结果则是一个 1-10 的总体打分。
在具体操作上,选择调用 GPT-4 来生成需要的评判。对于每个样本,都会将其对应场景的评估标准传入 GPT-4 中作为生成评判时的参考;此外,这里还观察到在部分样本上场景评估标准的加入会限制 GPT-4 发现回复中特殊的不足之处,因此研究者还额外要求其在给定的评估标准之外尽可能地发掘其他的关键因素。最终,会将来自上述两方面的输出进行融合与重新排版,得到更加全面、具体且易读的评判,作为训练数据的输出部分,其中对于成对回复比较数据,进一步根据已有的人类偏好标注进行了筛选。
训练:
研究者将来自两种评估范式的数据合并使用以训练模型,这使得 Auto-J 仅通过设置相应的提示词模板即可无缝切换不同的评估范式。另外,还采用了一种类似于上下文蒸馏的(context distillation)技术,在构建训练序列时删去了 GPT-4 用以参考的场景评估标准,仅保留了输出端的监督信号。在实践中发现这能够有效增强 Auto-J 的泛化性,避免其输出的评判仅限制在对评估标准的同义重复上而忽略回复中具体的细节。同时,对于成对回复比较数据部分,还采用了一个简单的数据增强方式,即交换两个回复在输入中出现的顺序,并对输出的评判文本进行相应的重写,以尽可能消除模型在评估时的位置偏好。
实验和结果
针对 Auto-J 所支持的多个功能,分别构建了不同的测试基准以验证其有效性:
在成对回复比较任务上,评估指标为与人类偏好标签的一致性,以及在交换输入中两个回复的顺序前后模型预测结果的一致性。可以看到 Auto-J 在两个指标上均显著超过了选取的基线模型,仅次于 GPT-4。
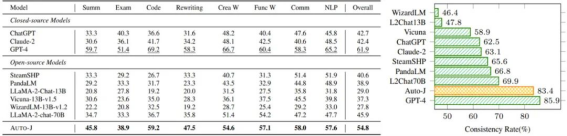
表 1 & 图 3:成对回复比较任务的结果
在单回复评论生成任务上,将 Auto-J 生成的评论与其他模型的评论进行了一对一比较,可以看到不管是基于 GPT-4 的自动比较还是人类给出的判决,Auto-J 所生成的评论都显著优于大部分基线,且略微优于 GPT-4。
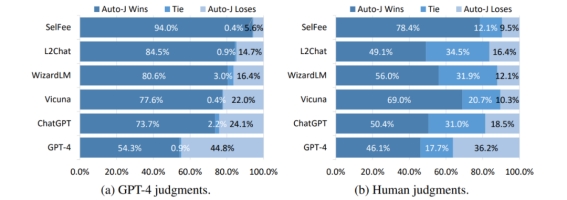
图 4:Auto-J 在单回复评论生成任务上相比基线的胜率
研究者还探索了 Auto-J 作为奖励模型(Reward Model)的潜力。在常用的检测奖励模型有效性的 Best-of-N 设定下(即基座模型生成多个候选答案,奖励模型根据自身输出选择最佳回复),Auto-J 给出的单回复打分比各类基线模型能选出更好的回复(以 GPT-4 评分为参考)。同时,其打分也显示了与 GPT-4 打分更高的相关性。
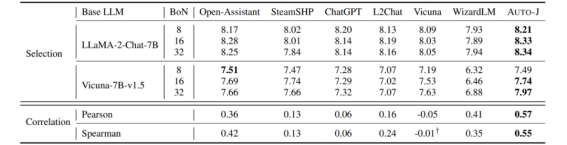
表 2:不同模型作为奖励模型的表现
最后,开发者也探究了 Auto-J 在系统级别的评估表现。对 AlpacaEval(一个流行的基于GPT-4评估的大模型排行榜)上提交的开源模型使用 Auto-J 的单样本打分进行了重新排序。可以看到,基于 Auto-J 的排序结果与 GPT-4 的排序结果有极高的相关性。
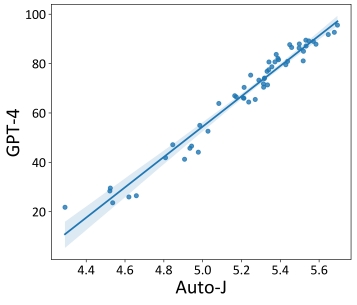
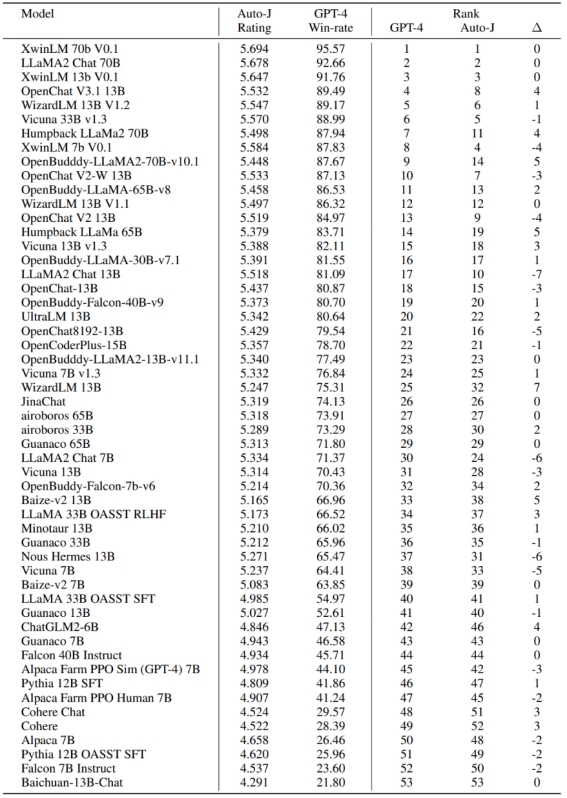
图 5 & 表 3:Auto-J 与 GPT-4 对 AlpacaEval 排行榜提交的开源模型排序之间的相关性及具体排名数据
总结和展望
总结来说,GAIR 研究组开发了一个具有 130 亿参数的生成式评价模型 Auto-J,用于评估各类模型在解决不同场景用户问询下的表现,并旨在解决在普适性、灵活性和可解释性方面的挑战。实验证明其性能显著优于诸多开源与闭源模型。此外,也公开了模型之外的其他资源,如模型的训练和多个测试基准中所使用的数据,在构建数据过程中得到的场景定义文件和参考评估标准,以及用以识别各类用户问询所属场景的分类器。
出自:https://mp.weixin.qq.com/s/YjCgSXn_aKUYKzpQrBg7BA
一个以人工智能为驱动的学习平台,Sana官网入口网址