超级干货,自学stable diffusion,看完这篇就够了
发布时间:2024年06月06日
这期我们要讲一讲它的一些实用插件、模型下载、提示词等。
本期将从以下4个模块逐步讲解:
sd提示词怎么写
sd模型下载
sd实用插件
Control Net插件讲解
*注意:文章内的链接不可直接跳转,需自行复制到浏览器打开!
#1
sd提示词怎么写
*提示词之间要用英文逗号隔开
*提示词之间是可以换行的
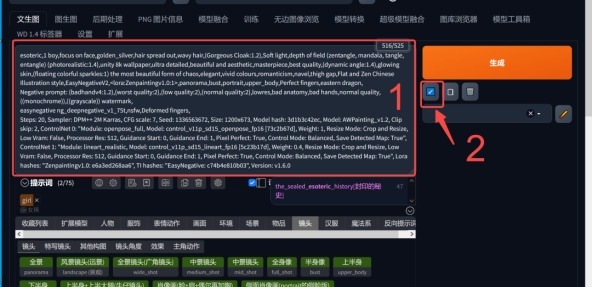
正向提示词例如:主体描述:一个女孩,长卷发,头发散开,五官精致,纤瘦。场景描述:山顶的寺庙,山,水,树,云,太阳,天。风格描述:中国风,禅意,浪漫主义。画面需求描述(常规提示词,可通用):柔和的光线,8k质量,超级详细,伟大的杰作,壁纸,生动的色彩,逼真,美丽,好看。补充描述:正常的的手指,完美的五官。
反向提示词:
常规提示词:(badhandv4:1.2),(worst quality:2),(low quality:2),(normal quality:2),lowres,bad anatomy,bad hands,normal quality,((monochrome)),((grayscale)) watermark, easynegative ng_deepnegative_v1_75t,nsfw,上面主要说的是一些质量差,丑,颜色单一之类的, 通用反向提示词,这个可以直接拿去用就行。基于画面的需求进行详细反向描述:例如这次的主体是人:畸形的手指,丑陋的五官,丑的。
*左图没写反向提示词的,右图增加了反向提示词的

提示词的权重:
提示词默认权重为1,如果你不进行权重的调整的话越靠前的提示词权重越高,但是如果你需要突出画面中某个元素,或者某个元素AI没有给你生成出来的话,就需要提高这个描述词的权重来突出这个内容。
加权重有两种方式:1.加括号(), 增加一个括号就增加0.1的权重, (美丽的)就是1.1的权重,((美丽的))就是1.2的权重。2.加括号和冒号(:),例如:(美丽的:1.5),就是1.5的权重。
比如我想要画面里有花,但是因为描述词比较多, 花的权重没有突出,ai就可能自己取舍或者没有很明显的花,这时候我们就增加花的权重, 让花在画面里的比例更大。
下方左图提示词:a girl, with long curly hair, loose hair, delicate facial features, and slender features, (Temple on the mountaintop:1.5), mountains, water, trees, clouds, sun, sky,flowerChinese style, Zen, Romanticism Soft lighting, 8k quality, super detailed, great masterpiece, wallpaper, vivid colors, realistic, beautiful, and good-looking
下方右图提示词:a girl, with long curly hair, loose hair, delicate facial features, and slender features, (Temple on the mountaintop:1.5), mountains, water, trees, clouds, sun, sky,(flower:2)Chinese style, Zen, Romanticism Soft lighting, 8k quality, super detailed, great masterpiece, wallpaper, vivid colors, realistic, beautiful, and good-looking
#2
sd模型下载
常用模型下载网址:
https://huggingface.co/
模型分为:
基础模型(大模型)
VAE模型(滤镜)
control net模型(插件辅助模型)
Lora模型(基于基础模型的风格调整模型)
模型安装位置:

模型放置位置记得要放一张相同同命名模型效果图片,这样stable diffusion就会识别到,展示的时候会展示这个图片,能快速找到需要的模型,没有放图片的话就会像第一个这样,显示图片缺失,要靠看下面的模型名称来分辨模型的作用。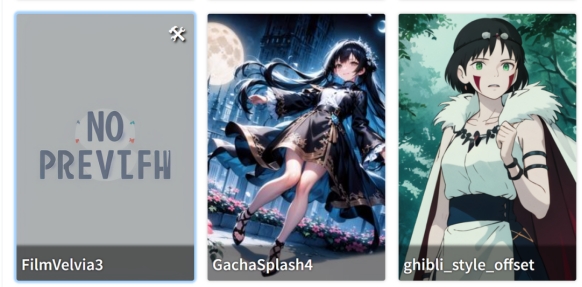
#3
sd实用插件
插件安装方法+地址:

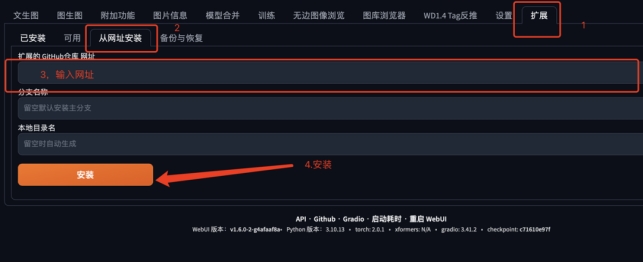
|
Tag自动补全 |
输入中文词语会弹出英文,直接点击使用 |
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete |
|
图库浏览器 |
浏览自己之前生成过的所有图片,可以分类, 分级 |
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser.git |
|
简体中文语言包 |
汉化插件 |
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN |
|
WD1.4 Tag反推插件 |
上传图片,会帮你把图片分析为描述词, |
https://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git |
|
sd-webui-prompt-all-in-one |
预设了很多AI可以理解的描述词 |
https://gitcode.net/ranting8323/sd-webui-prompt-all-in-one |
|
控制网络(ControlNet插件) |
篇幅比较长,后面第4个模块着重讲解这块 |
https://github.com/Mikubill/sd-webui-controlnet |
一、Tag自动补全:
词库, 输入中文后会跳出适合AI理解的英文选项。
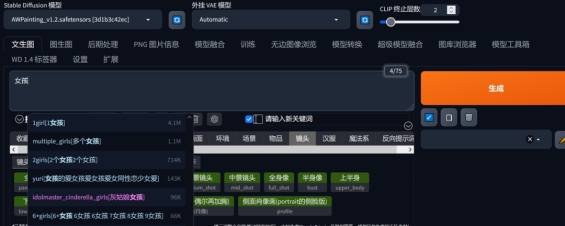
二、图库浏览器:
1.存留自己往期生成过的效果图,并保留该效果图的生成参数(模型,lore,迭代步数,采样,宽高等都会保留,插件数据不会保留),把图片信息完全复制到正向提示里,然后点击生成底部的箭头,这张图片的所有参数就会自己匹配到相应的位置。
2.对图片进行评级,便于后期筛选。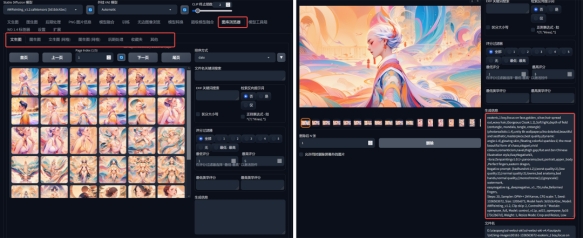
三、WD1.4 Tag反推插件:
把图片给到AI,AI反推完成后记得点击卸载所有反推模型,不然会占内存。
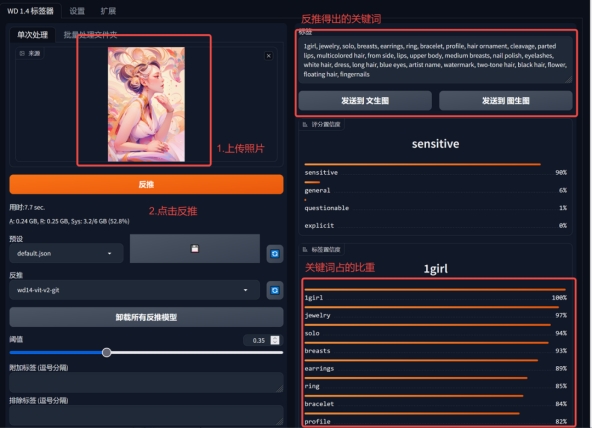
给反推插件的图像

选用同款模型后,直接用反推的关键词生成的结果

加入一个动作要求,生成的结果(结合ControlNet )

四.sd-webui-prompt-all-in-one
#4
Control Net插件讲解
一、控制网络(ControlNet插件):https://github.com/Mikubill/sd-webui-controlnet
安装方法见插件安装官方:contorlnet模型下载地址:https://huggingface.co/lllyasviel/ControlNet-v1-1/...
百度盘:链接:https://pan.baidu.com/s/125iUNB6fMjPcP2LKE3giFQ提取码:lylbSd
Sd生成图片图片的三个要素:描述、模型、control net
二、Control Net有什么用?
1.线稿上色2.小色稿-成稿3.照片动作提取4.线稿提取
1.线稿-上色(文生图)
首先准备一个线稿(干净一点的,因为sd不知道你什么线是要的,什么是不要的)。
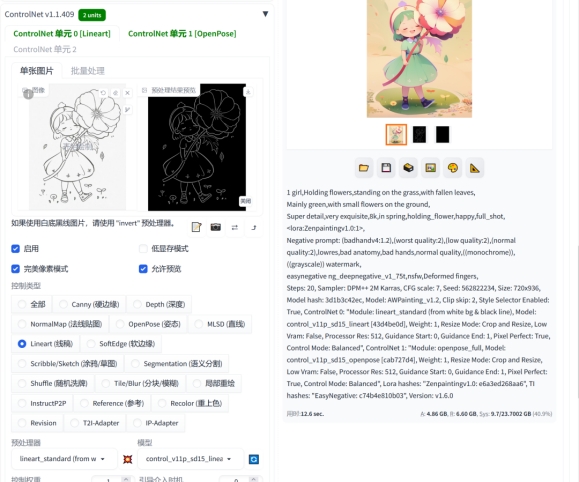



2.小色稿-成稿(图生图)
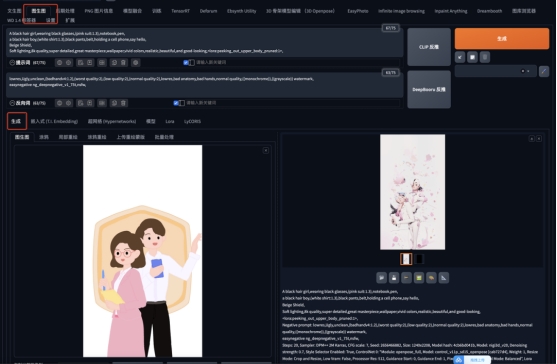
要用没有线条或者同色系线条的小色稿来进行生成效果会更好

以下分别是:
a.人工绘制产出(用时3天)
b.和需求方沟通好草图方向
c.草图+小色稿+AI产出,用时1天左右
3.动作提取
根据具体需求绘制一个草图;确定风格(找模型和Lora),直接对着sd说自己要的内容,输入关键词生成的结果;
点击编辑,调整一下动作,让它更像草图;加入一个动作要求,生成的结果(结合ControlNet );调整动作结构图+换一个模型得到的结果(需要锁定种子)。

4.线稿提取
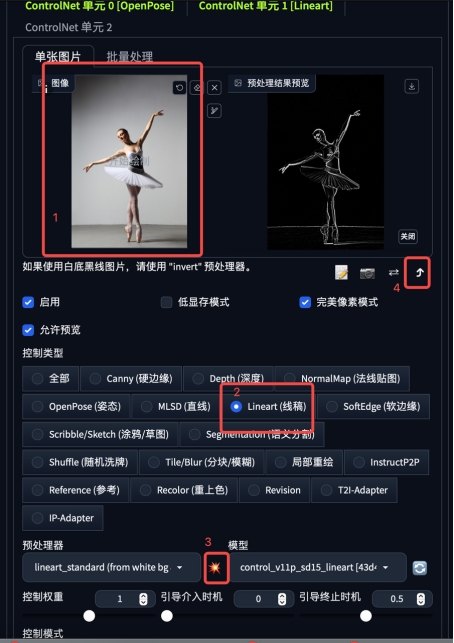


版权及免责声明:
部分图片来源于网络,如有侵权请联系删除
转载或引用本文内容请注明来源
出自:https://mp.weixin.qq.com/s/p7lmG139KnNHdtdYb3c1XQ
Ebsynth是一款基于人工智能的视频动漫化转换工具,轻松几步就可将视频素材转换为各种你想要的风格“动画”。