RAG超参数调优食用指南
发布时间:2024年06月06日
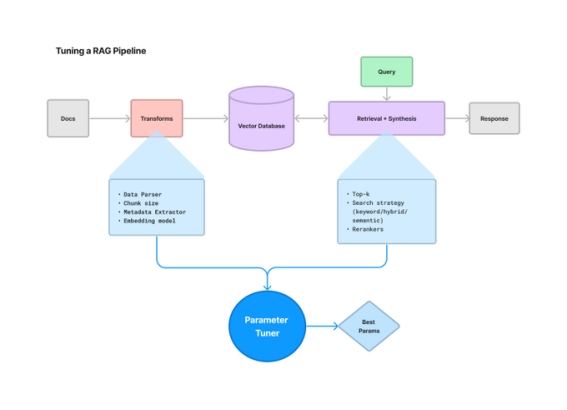
目前构建 LLM 应用程序存在一个巨大的问题,那就是需要调整大量的参数,而且远远超出了提示范围,例如分块、检索策略、元数据等。为了解决这些问题 LlamaIndex 推出了一个 ParamTuner 类,可以自动、高效地执行超参数调整。
ParamTuner 不仅可以定义我们想要的任何目标函数,例如带有评估的 RAG 管道;还能够以同步或者异步的方式进行网格搜索;并且 LlamaIndex 官方使用了 Ray Tune 将其提升到了一个新的水平。但是值得注意的是,该方法很有可能需要耗费很大的成本。
ParamTuner 有两种变体:
ParamTuner:一种通过遍历所有参数进行参数调优的简单方法。
RayTuneParamTuner:由 Ray tune 提供的超参数调优机制。
ParamTuner 可以接受任何输出值字典的函数。在这个设置中定义了一个函数,该函数从一组文档(Llama2 论文)构造一个基本的 RAG 摄取管道,选择最合适的评估数据集并运行它,最后为运行结果打分。
接下来将用一个完整的使用指南来展示如何对 RAG 进行超参数优化,主要针对块大小和 top-K 两个参数。
本文将会包括以下内容:
1.什么是超参数微调,以及为什么它很重要
2.超参数搜索的类型
3.ParamTuner 食用指南
01
什么是超参数调优,以及为什么它很重要
首先介绍超参数,超参数是模型不能从给定数据中估计的参数,是控制模型整体行为的变量。
超参数调优是一个过程,用于确定如何正确组合超参数以最大化模型性能。它涉及运行多个试验,每个试验都是训练程序的完整执行,采用不同的超参数设置值在指定范围内进行训练。一旦这一过程完成,将提供一组最适合模型的超参数值,以获得最佳结果。学习率就是一个很好的例子。当它太大时,学习不够灵敏,模型结果不稳定;但当它太小时,模型就会难以学习并且可能会卡住。
从上述介绍中不难看出,超参数调优是一个比较重要的步骤,因为它能够影响模型的最终的性能。
02
超参数搜索的类型
执行超参数搜索主要有以下三种方法:网格搜索、随机搜索和贝叶斯搜索。
网格搜索
网格搜索执行超参数调整的基本方法是尝试所有可能的参数组合。它在每一个可能的超参数组合上拟合模型并记录模型的性能。最后,它返回具有最佳超参数的最佳模型。这也是本文的方法用到的方式。
随机搜索
在随机搜索中,仅尝试部分参数值。采样的参数设置数量由 n_iter 给出。参数值是从给定列表或指定分布中采样的。当参数以列表形式呈现时(如网格搜索),将执行无替换采样。但如果参数以分布形式给出,一般使用放回抽样。
贝叶斯搜索
贝叶斯搜索与其他方法的主要区别在于,调整算法根据上一轮的得分来优化每轮的参数选择。因此,该算法不是随机选择下一组参数,而是优化选择,并且可能比前两种方法更快地达到最佳参数集。这意味着,此方法仅选择相关搜索空间并丢弃很可能无法提供最佳解决方案的范围。因此,该方法比较适用于当我们拥有大量数据、学习速度很慢并且希望最大限度地减少调整时间的情况。
03
ParamTuner 食用指南
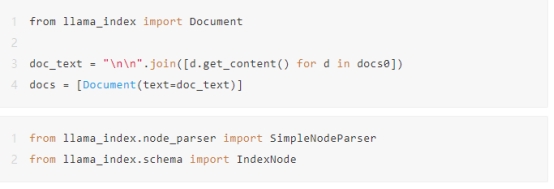
首先我们来配置一下环境

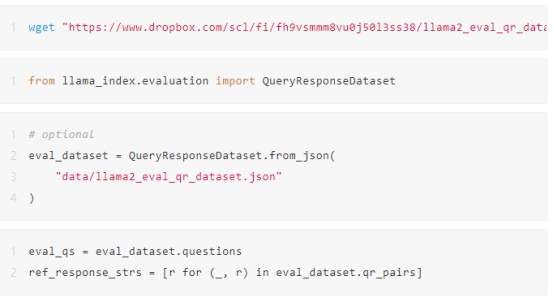
加载合适的评估数据集
在这里,我们为 llama2 论文建立了一个“黄金”评价数据集。
需要注意的是,数据集从 Dropbox 中提取。有关如何生成数据集的详细信息,可以参阅 LlamaIndex GitHub主页的 DatasetGenerator 模块。
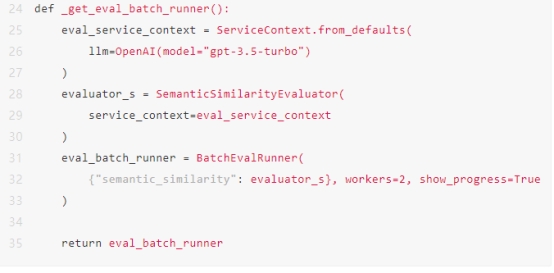
定义目标函数和参数
这里我们定义函数来优化给定的参数。该函数具体执行以下操作:
1.从文档构建索引,
2.查询索引,并运行一些基本计算。

辅助函数

同步目标函数


异步目标函数


参数定义
这部分定义了在 param_dict 上进行网格搜索的参数和固定参数 fixed_param_dict。

运行默认的ParamTuner
这里我们运行默认的参数调优器,它以同步或异步方式迭代所有超参数组合。

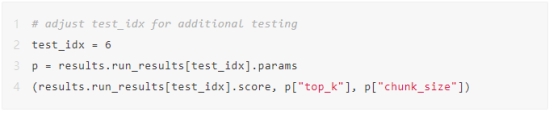
运行异步ParamTuner

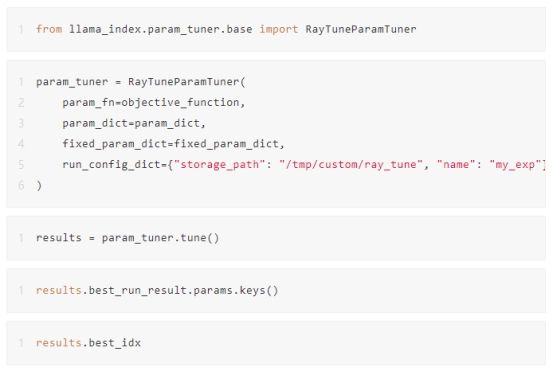
用Ray Tune运行ParamTuner
在这里,我们运行由 Ray Tune 提供支持的调谐器,Ray Tune 是一个用于任意规模的实验执行和超参数调整的 Python 库,集成了各种额外的超参数优化工具,包括 Ax、BayesOpt、BOHB、Dragonfly、FLAML、Hyperopt、Nevergrad、Optuna 和 SigOpt。
本指南中,我们在本地运行它,但其实也可以在集群上运行它。

出自:https://mp.weixin.qq.com/s/Yc_WwIN1_0XVdRpUuS9IoA
句易网为您提供最新广告法淘宝抖音违禁词在线过滤工具。