QWen1.5: 卓越模型之路
发布时间:2024年06月06日
引言
在QWen升级之路一文中,我们深入探究了千问模型的优化过程,新版千问1.5模型较原先又取得的提升,本文将继续分析新版千问1.5模型取得不俗表现的原因。
文章结构如下:
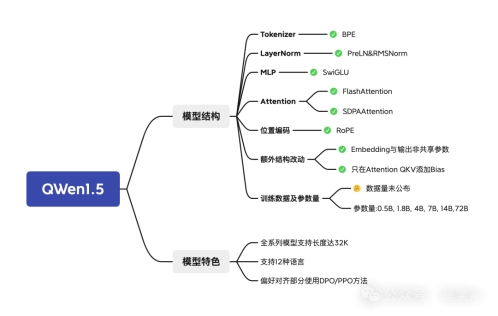
QWen1.5
QWen1.5性能
首先,我们跟随千问1.5技术报告了解其具体的性能表现。

在此次Qwen1.5版本中,开源了包括0.5B、1.8B、4B、7B、14B和72B在内的6个不同规模的Base和Chat模型,并一如既往地放出了各规模对应的量化模型。
对 Qwen Base 和 Chat 模型在一系列基础及扩展能力上进行了详尽评估,包括如语言理解、代码、推理等在内的基础能力,多语言能力,人类偏好对齐能力,智能体能力,检索增强生成能力(RAG)等,对比对象也增加了热门的Mixtral MoE模型。
 1IXxvg
1IXxvg
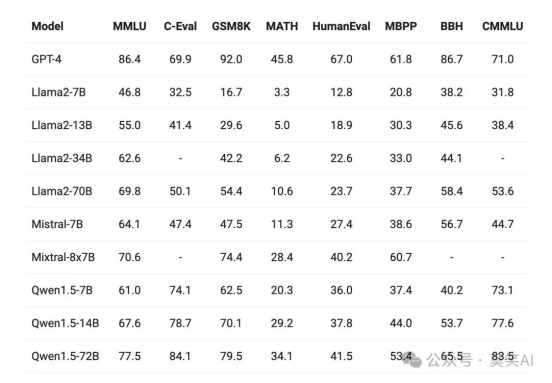
在不同模型尺寸下,Qwen1.5 都在评估基准中表现出强劲的性能。特别是,Qwen1.5-72B 在所有基准测试中都远远超越了Llama2-70B,展示了其在语言理解、推理和数学方面的卓越能力。
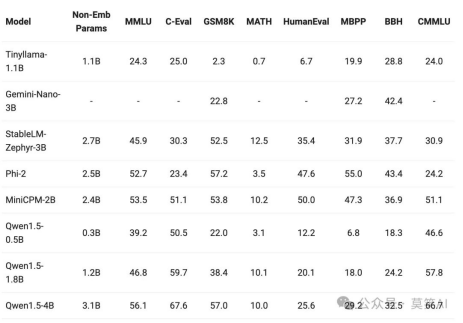
小型模型的构建也成为了热点之一,将模型参数小于 70 亿的 Qwen1.5 模型与社区中最杰出的小型模型进行了比较。结果如下:
o3Exer
人类偏好对齐
在对齐最新的 Qwen1.5 系列时有效地采用了直接策略优化(DPO)和近端策略优化(PPO)等技术。评估结果如下:
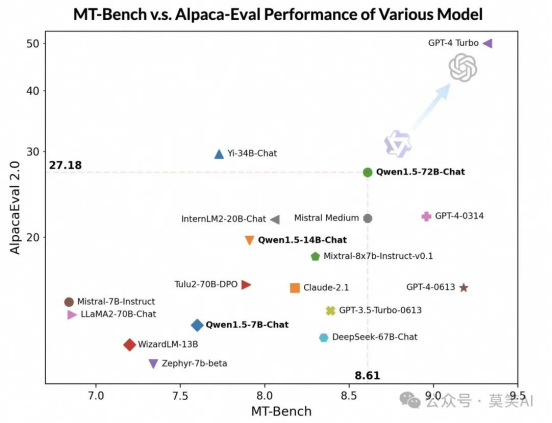
尽管落后于 GPT-4-Turbo,但最大的 Qwen1.5 模型 Qwen1.5-72B-Chat 在 MT-Bench 和 Alpaca-Eval v2 上都表现出不俗的效果,超过了 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct 和 TULU 2 DPO 70B,与 Mistral Medium 不相上下。
多语言能力
评测数据:挑选了来自欧洲、东亚和东南亚的12种不同语言,全面评估Base模型的多语言能力。从开源社区的公开数据集中,我们构建了如下表所示的评测集合,共涵盖四个不同的维度:考试、理解、翻译、数学。下表提供了每个测试集的详细信息,包括其评测配置、评价指标以及所涉及的具体语言种类。
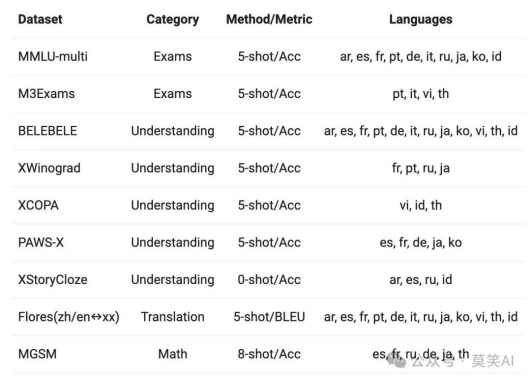
m5MXDh
base模型表现如下:
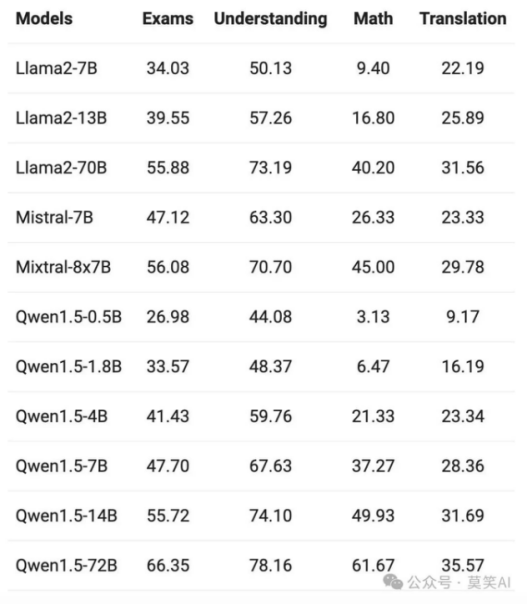
aOPGrX
Qwen1.5 Base模型在12种不同语言的多语言能力方面表现出色,在考试、理解、翻译和数学等各个维度的评估中,均展现优异结果。不论阿拉伯语、西班牙语、法语、日语,还是韩语、泰语,Qwen1.5均展示了在不同语言环境中理解和生成高质量内容的能力。、
Chat模型表现如下:
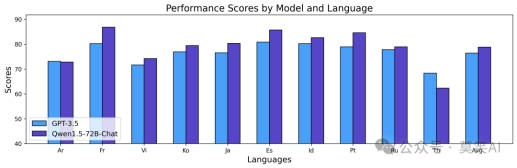
上述结果展示了Qwen1.5 Chat模型强大的多语言能力,可用于翻译、语言理解和多语言聊天等下游应用。我们相信多语言能力的提升,对于其整体通用能力也具有正向的作用。
长序列
这次推出的 Qwen1.5 模型全系列支持 32K tokens 的上下文。在L-Eval 基准上评估了 Qwen1.5 模型的性能,该基准衡量了模型根据长输入生成答案的能力。结果如下:
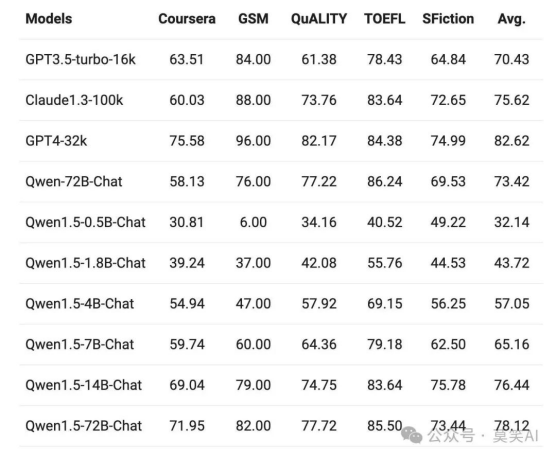 3ZHRWb
3ZHRWb
从结果来看,即使像 Qwen1.5-7B-Chat 这样的小规模模型,在上面大5个任务中的4个表现出与 GPT3.5-turbo-16k 类似的性能。而最好的模型 Qwen1.5-72B-Chat,仅略微落后于 GPT4-32k。
此外,可以在 config.json 中,将 max_position_embedding 和 sliding_window 尝试修改为更大的值,支持更大的上下文长度。
工具使用效果
RAG
对 Qwen1.5 系列 Chat 模型,在 RAG 任务上的端到端效果进行了评估。评测基于 RGB 测试集,是一个用于中英文 RAG 评估的集合:
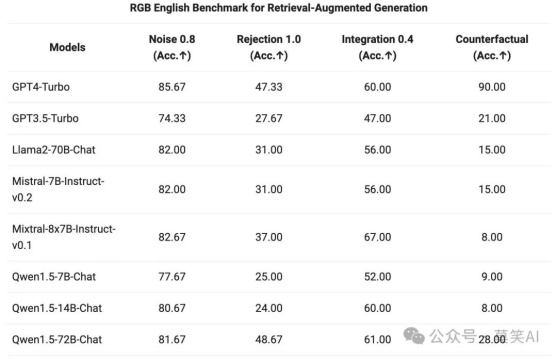 Ht9ajt
Ht9ajt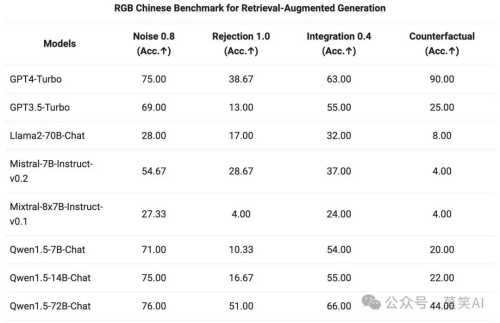
GR3qwb
Agent
在T-Eval 基准测试中评估了 Qwen1.5 作为通用代理运行的能力。所有 Qwen1.5 模型都没有经过专门针对该基准的优化:
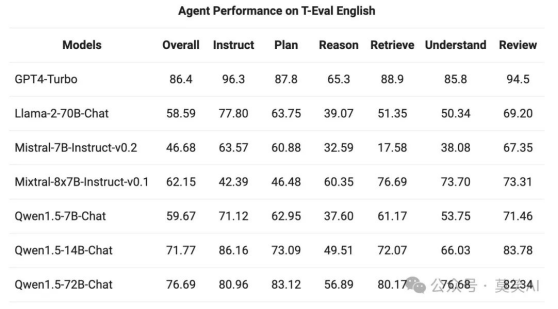 6fyRDy
6fyRDy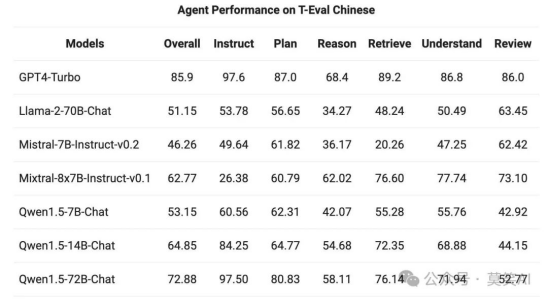 Iyqfk4
Iyqfk4
Tool use
为了测试工具调用能力,使用开源的 评估基准 ,测试模型正确选择、调用工具的能力,结果如下:
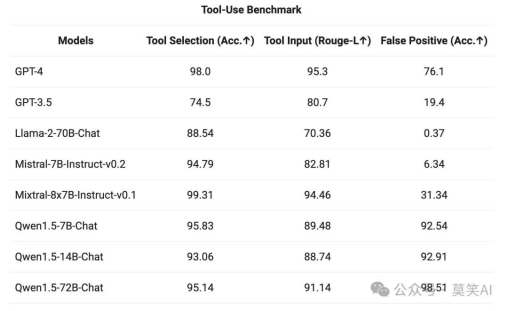
GYq7Ri
Code Interpreter
由于 Python 代码解释器已成为高级 LLM 越来越强大的工具,还在之前qwen开源的 评估基准 上评估了qwen模型利用这一工具的能力:
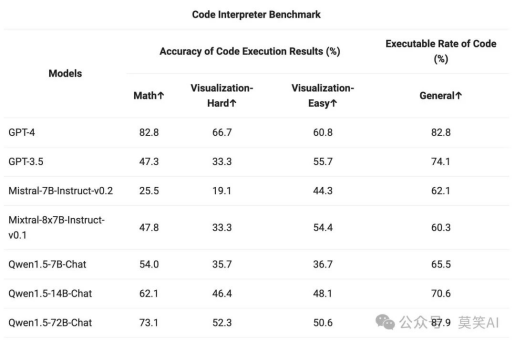
SWQhlv
较大的 Qwen1.5-Chat 模型通常优于较小的模型,接近 GPT-4 的工具使用性能。不过,在数学解题和可视化等代码解释器任务中,即使是最大的 Qwen1.5-72B-Chat 模型,也会因编码能力而明显落后于 GPT-4。Qwen的目标是在未来的版本中,在预训练和对齐过程中提高所有 Qwen 模型的编码能力。
Qwen1.5结构对比
在了解QWen1.5性能表现后,我们来跟随代码查看下QWen1.5模型的结构:
huggingface的文件中没有给出qwen1.5的modeling文件,但是可以通过安装transformers>=4.37.0版本,查看模型具体结构:
具体路径为:
/xxxenv/lib/python3.10/site-packages/transformers/models/qwen1.5/
 T6h81D
T6h81D
输出层与输入层参数共享
 MSrcG2
MSrcG2
参数共享的模型加载方式
参考内容:https://zhuanlan.zhihu.com/p/642255416
PreTrainedModel.from_pretrained调用tie_weights方法,是的,就是tie_weights方法将embedding层和lm_head层绑定的。
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L2927
model.is_loaded_in_4bit = load_in_4bit
model.is_loaded_in_8bit = load_in_8bit
model.is_quantized = load_in_8bit or load_in_4bit
# make sure token embedding weights are still tied if needed
model.tie_weights()
# Set model in evaluation mode to deactivate DropOut modules by default
model.eval()
· tie_weights方法是如何将embedding层和lm_head层绑定的?接下来解读其代码。
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L1264
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
If the `torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning the
weights instead.
"""
if getattr(self.config, "tie_word_embeddings", True):
output_embeddings = self.get_output_embeddings()
if output_embeddings is not None:
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
if getattr(self.config, "is_encoder_decoder", False) and getattr(self.config, "tie_encoder_decoder", False):
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
for module in self.modules():
if hasattr(module, "_tie_weights"):
module._tie_weights()
· 他会检查你模型的config里面有没有tie_word_embeddings属性,只有在你明确表明tie_word_embeddings=False的时候,才不会进行权重绑定。
· 取模型的embedding层,然后调用_tie_or_clone_weights方法,将模型权重从embedding层复制给lm_head层。
· 那_tie_or_clone_weights方法到底是怎么复制的,下面是他的代码。
· 使用了nn.Parameter来做包裹,然后复制。
· 检测你是否用了偏置(bias),如果用到了,也要复制。
· 其实这里就是最核心的部分:虽然在我们眼里,在训练的过程中,是不同网络层进行梯度更新,实际上是网络层绑定的权重进行梯度更新。
· 虽然权重从一个网络层复制给另外一个网络层,但是这个权重并不是重新在内存上复制一份,而只是把参数更新的权利给到另外一个网络。类似于python对象的浅拷贝:只是网络层A和网络层B都指向了权重,却不能独享和内存复制。
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L1360
def _tie_or_clone_weights(self, output_embeddings, input_embeddings):
"""Tie or clone module weights depending of whether we are using TorchScript or not"""
if self.config.torchscript:
output_embeddings.weight = nn.Parameter(input_embeddings.weight.clone())
else:
output_embeddings.weight = input_embeddings.weight
if getattr(output_embeddings, "bias", None) is not None:
output_embeddings.bias.data = nn.functional.pad(
output_embeddings.bias.data,
(
0,
output_embeddings.weight.shape[0] - output_embeddings.bias.shape[0],
),
"constant",
0,
)
if hasattr(output_embeddings, "out_features") and hasattr(input_embeddings, "num_embeddings"):
output_embeddings.out_features = input_embeddings.num_embeddings
Attention QKV-Bias
线性层中只有Attention QKV的bias为True
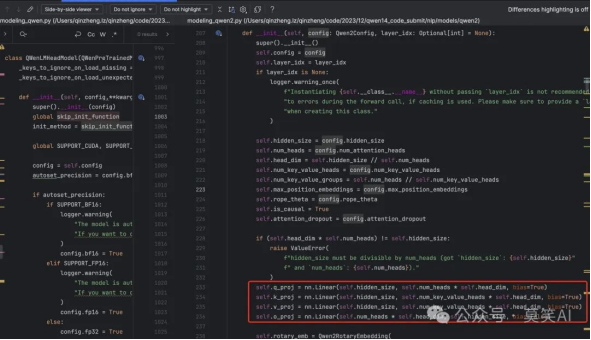 ak4Zrt
ak4Zrt
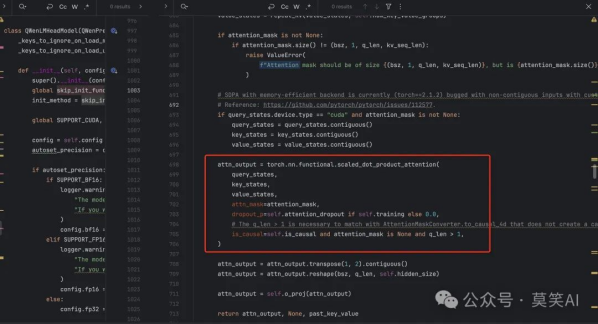
SDPA Attention
与Attention的实现在于使用SDPA的API
Qwen2 attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
Qwen2Attention as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
SDPA API.
 A9SdSF
A9SdSF
总结
本文详细介绍了新版本QWen1.5模型的性能表现以及模型结构。从整体来看QWen1.5模型较第一代模型从结构上未进行明显升级,但模型在下游任务关注的部分实现了优化和增强。QWen1.5全系列模型支持32K的上下文长度,多语言能力得到加强,此外,QWen1.5结合了DPO/PPO等策略,进一步优化了偏好对齐功能。在之前的分析中,我们指出QWen系列模型在训练过程中使用的Token数量超过了同级别模型,这可能是该模型卓越性能背后的关键因素。随着QWen1.5版本的推出,我们推测其训练Token数量可能已经得到了扩充,为模型带来进一步的性能提升。
出自:https://mp.weixin.qq.com/s/fz4H2AgS5jIEM7x1vGDObA
一种AI驱动可简化科学研究的统计分析过程的工具。Hepta AI为科学研究提供人工智能驱动的统计和数据分析,包括创建表格、图形和统计分析描述。