免训练!单图秒级别生成AI写真,人像生成进入无需训练的单阶段时代
发布时间:2024年06月06日
 介绍
介绍
作为 AI 人像写真开源项目的佼佼者,FaceChain 凭借其丰富多样的风格模版和卓越的人像保真度,深受社区的喜爱并已在商业应用中得到了广泛的应用。近期,FaceChain 团队推出了全新的版本——FaceChain FACT。这一创新版本摒弃了传统的人物模型训练过程,能够直接生成 zero-shot 目标人像,引领 AI 人像生成进入了无需训练的单阶段时代。
你是否曾经因为相册里只有寥寥几张照片而无法训练自己的数字形象而感到苦恼?或者因为需要等待 20 分钟左右的人物形象训练而感到焦急?
目前市场上的 AI 写真大多采用“训练+生成”的两阶段模式,既需要庞大的形象数据支撑,也需要一定的训练时间。这种模式增加了用户的使用成本。面对这一问题,FaceChain 给出了解决方案:无需大量数据,无需训练等待,甚至无需训练,只需要一张图片 10 秒钟即可立即生成 AI 写真!

原理
FaceChain FACT(Face Adapter)之所以能够跳过训练阶段,是因为它经过了百万级别的写真数据训练,从而使得 Stable Diffusion 具备了强大的人脸重建能力。
与传统的双阶段人像生成方法不同,FaceChain FACT 重新构建了 Stable Diffusion 模型的架构,使其能够将人脸信息作为独立分枝的条件,平行于文本信息一起送入模型中进行推理。通过这种方式,FaceChain FACT 能够更高效地处理人脸重建任务,从而避免了繁琐的训练阶段。FACT 整个框架如下图所示:
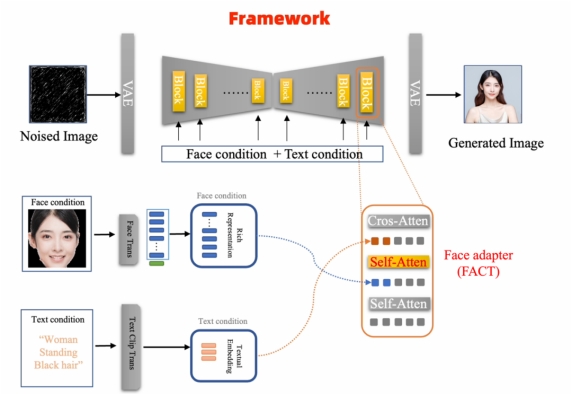
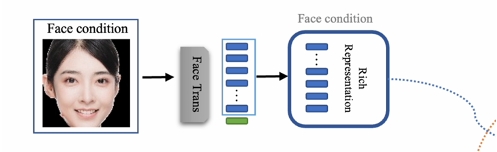
为了更全面地提取人脸的细节信息,FACT 采用了在海量人脸数据上预训练的基于 Transformer 架构的人脸特征提取器。与 CNN 架构的特征不同,基于 Transformer 架构的特征能够更好的适应 Stable Diffusion 的结构。通过这种方式,FACT 能够更精确地保留人脸的细节特征,从而实现高清的人脸重建。
为了确保 Stable Diffusion 的原有功能得到充分保留,FACT 作为独立的 adapter 层被插入到原始 Stable Diffusion 的 block 中,并在训练时固定原始 block 参数,仅对 adapter 进行训练。
此外,人脸特征与文本特征是相互独立的,平行送入 block 中,避免了彼此之间的干扰。通过调整人脸信号的权重,用户可以灵活地调节生成效果,从而在保持 Stable Diffusion 原有的文生图功能的同时,平衡人脸的保真度与泛化性。
 效果
效果
在 FACT 的加持下,FaceChain 的人像生成体验又有了质的飞跃。
1. 在生成速度方面,FaceChain-FACT 成功摆脱了冗长繁琐的训练阶段,将定制人像的生成时间大幅缩短了百倍。现在,整个生成过程仅需 10s 左右,为用户带来了无比流畅的使用体验。
2. 在生成效果方面,FaceChain-FACT 成功提升了人脸的细腻程度,使其更加逼近真实的人像效果。通过高度保留的人脸细节信息,确保了生成写真效果既惊艳又自然。FaceChain 海量的精美风格模版,又为生成的人像注入了艺术生命力。



FaceChain-FACT 的诞生,将为用户开启前所未有的高质量 AI 写真体验。除了在生成速度与质量上的显著提升,FaceChain 还提供丰富的 API 接口,让开发者可以根据自己的需求进行定制化开发。
无论是想要创建自己的 AI 写真应用,还是在现有项目中集成 FaceChain 的功能,都可以轻松实现。我们深知创新与定制化的重要性,因此我们将不断探索和加入新的风格模版,以及更多有趣的功能。我们热忱欢迎对开源技术感兴趣的朋友们加入我们,共同引领 AIGC 文生图领域迈向崭新的时代!
 参考项目主页:
参考项目主页:
https://facechain-fact.github.io/
Github项目:
https://github.com/modelscope/facechain
出自:https://mp.weixin.qq.com/s/QazZ7AAbkUeYFWr0xC1JVQ
一个开源的视频翻译和配音工具,VideoTrans能够一键识别视频字幕、翻译成其他语言以及进行多种语音合成,最终输出带字幕和配音的目标语言的视频。