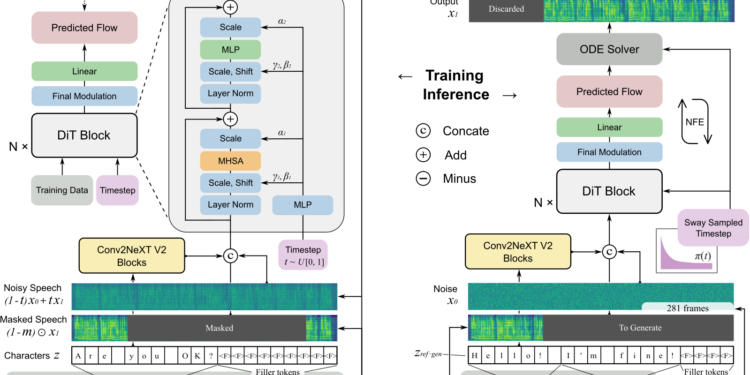
F5-TTS 是一种完全非自回归的文本转语音(Text-to-Speech, TTS)系统,该系统基于流匹配技术和扩散变换器(DiT),旨在实现高效、自然且准确的语音生成。
它不像传统的系统那样一步一步生成语音,而是能够同时处理多个步骤,这让它的速度更快。
通过简化模型设计、提升推理效率和生成质量,解决了现有TTS系统在对齐复杂性、推理延迟和生成自然度等方面的不足。这使得F5-TTS能够在多语言、多场景下提供自然、流畅、准确的语音生成服务。
该模型的设计解决了当前TTS系统中存在的一些关键问题,具体如下:
- 速度快:传统系统需要逐步生成语音,而 F5-TTS 可以同时处理多个步骤,加快生成速度。
- 简化的模型设计:其他系统需要复杂的音素对齐和预测,而 F5-TTS 简化了流程,不需要这些复杂步骤。
- 高效的推理:推理速度显著提升,适合大规模应用场景,特别是在实时语音生成和多语言支持方面表现优异。
- 生成质量:即使在零样本条件下,F5-TTS依然能够生成自然、准确的语音,并支持不同语言之间的无缝切换。
功能特点:
- 快速语音生成能力
- F5-TTS 采用非自回归架构,能够一次性生成整段语音,相比于逐帧生成的自回归模型,生成速度大幅提升。
- 利用 Sway 采样策略,推理效率显著提升,推理时的实时因子(RTF)达到 0.15,远超当前的扩散模型。这使得 F5-TTS 可以快速生成高质量语音,适用于需要实时响应的应用场景。
- 多语言支持与零样本生成
- F5-TTS 在一个包含 100K 小时的多语言数据集上进行训练,具备出色的 多语言处理能力。它能够自然地生成多种语言的语音,并能在不同语言之间无缝切换,处理复杂的多语言输入。
- 零样本生成能力:F5-TTS 能够生成从未训练过的语言的语音,即便该语言没有包含在训练数据集中,它仍然能够生成自然流畅的语音。
视频播放器00:0000:00
- 语言切换(Code-Switching)
- F5-TTS 支持在同一段语音中进行 语言切换,即跨语言生成语音。例如,在一段语音中,它可以从英语切换到中文,然后再切换回英语,这种能力在多语言对话场景中尤为重要。
视频播放器00:0000:00
- F5-TTS 支持在同一段语音中进行 语言切换,即跨语言生成语音。例如,在一段语音中,它可以从英语切换到中文,然后再切换回英语,这种能力在多语言对话场景中尤为重要。
- 语速控制
- F5-TTS 支持 语速控制,用户可以指定语音的总时长,模型会根据指定的时长自动调整语速,生成符合用户需求的不同速度版本的语音。例如,可以根据需要生成慢速、中速或快速语音。
视频播放器00:0000:00
- F5-TTS 支持 语速控制,用户可以指定语音的总时长,模型会根据指定的时长自动调整语速,生成符合用户需求的不同速度版本的语音。例如,可以根据需要生成慢速、中速或快速语音。
- 情感表达
- F5-TTS 具备生成 带有情感的语音 的能力,能够根据输入文本的情感信息生成相应的语音情感表现,如愤怒、快乐、悲伤等。这使得生成的语音更加生动、自然,适用于需要情感表达的场景,例如有声读物、虚拟助理等。
视频播放器00:0000:00
- F5-TTS 具备生成 带有情感的语音 的能力,能够根据输入文本的情感信息生成相应的语音情感表现,如愤怒、快乐、悲伤等。这使得生成的语音更加生动、自然,适用于需要情感表达的场景,例如有声读物、虚拟助理等。
- 高鲁棒性
- F5-TTS 在处理复杂文本输入时表现出色的 鲁棒性。无论输入的句子多么复杂或难以处理,F5-TTS 仍能生成高质量的语音。这种能力使得它能够处理包括长句子、复杂语言结构甚至是口语化表达的文本输入,生成流畅的语音输出。
视频播放器00:0000:00
- F5-TTS 在处理复杂文本输入时表现出色的 鲁棒性。无论输入的句子多么复杂或难以处理,F5-TTS 仍能生成高质量的语音。这种能力使得它能够处理包括长句子、复杂语言结构甚至是口语化表达的文本输入,生成流畅的语音输出。
视频转文字,录音转文字,图片转文字,20M以内不用注册也可以用。