
Playground v3(PGv3)是由Playground开发的一种文本到图像生成模型,其基于最新的大语言模型(LLMs)设计,在多语言理解、精确的RGB颜色控制、图像与文本的对齐等方面表现出色。
该模型突破了传统依赖T5或CLIP文本编码器的方式,完全整合了大语言模型(例如Llama3-8B)的能力,以提高对复杂文本提示的理解与生成。
 Playground v3(PGv3)模型在文本到图像生成过程中,引入了一种全新的文本处理方式,与传统方法相比具有显著的创新性。
Playground v3(PGv3)模型在文本到图像生成过程中,引入了一种全新的文本处理方式,与传统方法相比具有显著的创新性。
传统方法:依赖T5或CLIP文本编码器
在以往的文本到图像生成模型中,常用的文本处理方式是通过T5或CLIP这样的预训练模型来将文本转换成适合图像生成的输入条件。这些预训练模型主要做的是将输入的自然语言文本转换为向量表示(即高维数值向量),这些向量可以作为扩散模型(如生成图像的核心模块)的条件输入,用来指导图像的生成。
- T5模型是一种基于Transformer架构的文本编码器,它通过大量文本语料的预训练,能够将自然语言文本编码为语义向量,捕捉句子中的语言模式和语义关系。
- CLIP模型(Contrastive Language–Image Pretraining)则通过联合训练文本和图像,以确保文本与图像的表示方式在同一个空间中能够很好的对齐。CLIP的作用是帮助模型更好地理解文本与图像之间的关系,以实现生成文本描述对应的图像。
这些传统方法虽然在文本到图像生成任务中发挥了很大作用,但它们在面对复杂、详细的文本提示时往往存在不足,特别是在提示词的复杂推理和生成细节方面,常常达不到很高的精确度。
PGv3模型的突破:完全整合大型语言模型(LLM)
Playground v3(PGv3)模型不再依赖T5或CLIP这样的单独文本编码器,而是直接使用一个强大的大语言模型(LLM)来处理文本提示。具体来说,PGv3引入了Llama3-8B 作为核心的语言模型。Llama3-8B是一个解码器式的LLM,它不仅能对文本进行高度复杂的理解,还能帮助指导生成与文本紧密相关的图像。
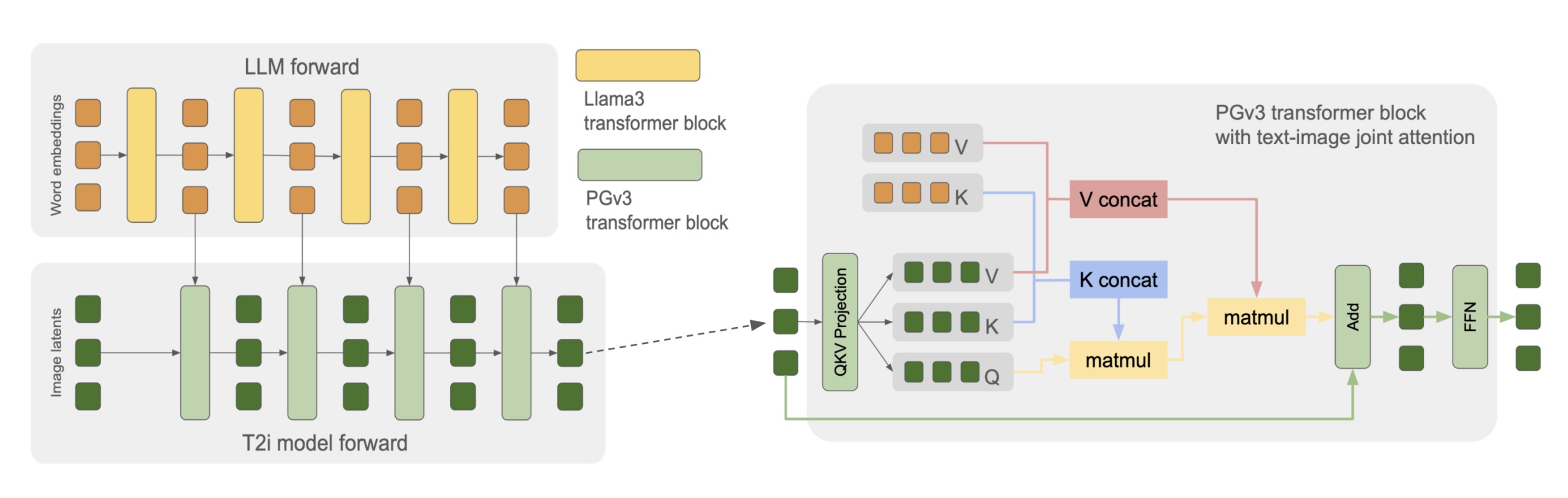
- LLM的作用:LLM(大语言模型)具有极强的语言理解和生成能力。相比传统的文本编码器,LLM不仅仅是将文本“翻译”成简单的语义向量,而是能够理解文本中更复杂的语义、逻辑和推理关系。例如,当用户输入的文本提示非常复杂,涉及多层次的逻辑、修辞和隐喻时,LLM能够更好地理解这些复杂关系,从而生成更符合预期的图像。在PGv3模型中,LLM不仅仅是作为文本编码器,它的每一层都参与了图像生成过程。模型通过从LLM的每一层提取隐藏层的输出作为条件输入,使得扩散模型能够更准确地反映出文本提示的复杂性。这种做法的核心思想是,LLM在每一层的输出中都携带了不同层次的语义信息,而不局限于最后一层。因此,通过使用整个模型的多层次信息,PGv3模型能够充分利用LLM的推理能力,生成与文本描述高度匹配的图像。
与传统文本编码器的比较
- 传统文本编码器(T5/CLIP):
- 局限性:这些编码器的输出主要依赖于最终的文本向量表示,信息往往被压缩成固定的向量,不足以全面反映文本中的多层次信息,特别是在处理长篇或复杂文本时,容易丢失细节。
- 应用场景:适用于较简单的文本提示,且对于图像生成任务中,文本的条件化输入较为单一,通常只能捕捉大致的语义,而对复杂推理和详细提示的生成能力有限。
- PGv3模型整合的LLM:
- 优势:LLM不仅能理解词语间的复杂语义关系,还能进行复杂的逻辑推理。由于每一层的隐藏状态都被用于生成过程,因此PGv3能够逐层提取语言模型中的深层语义信息,这比传统的只使用最后一层的文本编码器要更为有效。具体来说,LLM的不同层次能捕捉到从词汇级别到段落级别的各种语言特征,极大地提高了文本理解的精细度和生成的多样性。
- 效果:这种方法让PGv3在处理复杂提示(例如多角色、复杂场景、细节丰富的文本描述)时能够生成高度匹配的图像,不仅在内容上与文本提示精确对齐,还能捕捉文本中的隐含语义和情感等更深层次的信息。
为什么这是一个突破
这种整合LLM的方式代表着文本到图像生成技术的重大进步,因为它摆脱了传统方法中对固定文本编码器的依赖,利用了LLM强大的推理能力,显著提升了模型在处理复杂文本提示时的生成精确度和多样性。这种方式不仅提升了生成的图像质量,还在图像的细节、颜色控制、文本渲染等方面表现出了优异的能力。
主要能力
1. 高级文本理解与生成能力
1.1 LLM 深度整合
PGv3 通过深度整合大型语言模型 (LLM)(如 Llama3-8B),实现了对复杂文本提示的精准理解与图像生成。相比传统的文本编码器 (如 T5 或 CLIP),PGv3 能够更好地捕捉文本中的复杂语义、逻辑关系和细节描述,并将这些信息转化为符合文本提示的高质量图像。
- 多层次文本理解:LLM 的不同层次提供了更丰富的语义信息,能够处理简单和复杂提示,从简单的图像生成到多角色、多对象的复杂场景生成。
- 推理能力增强:PGv3 能够基于复杂的文本提示进行高级推理,处理多个实体之间的关系(如空间位置、颜色匹配、大小等),生成更符合实际需求的图像。
1.2 多级别文本描述生成
PGv3 支持多级别的文本描述生成,能够根据不同的复杂度要求,生成从细节丰富到概念抽象的图像。
- 多层次描述:通过使用多层次描述生成器,PGv3 可以生成不同详细程度的图像描述,适应不同的设计任务需求。例如,详细的广告描述或简要的场景提示都可以生成高质量图像。

2. 精细的图像生成与控制能力
2.1 高质量图像生成
PGv3 使用了 Latent Diffusion Model (LDM) 和 DiT (Diffusion Transformer) 架构,结合 LLM 的文本理解能力,生成的图像在质量和细节上都表现出色。

- 细节丰富:生成的图像在细节处理上具有高精度,能够在复杂场景中呈现多样化的元素,包括多个角色、复杂的背景和特定的光影效果。
 照片真实感的定性比较:左上角是 Ideogram-2,右上角是 PGv3,左下角是 Flux-pro,右下角是提示。放大以便更好地比较细节和纹理。
照片真实感的定性比较:左上角是 Ideogram-2,右上角是 PGv3,左下角是 Flux-pro,右下角是提示。放大以便更好地比较细节和纹理。 - 真实感:PGv3 在生成逼真的图像方面表现出色,特别是在照片级图像生成和艺术创作方面,如人像、风景等具有高度的真实感。
 PGv3 的照片级真实感定性结果
PGv3 的照片级真实感定性结果

使用简单短提示从 PGv3 生成图像
2.2 RGB 颜色精确控制
PGv3 的一大特色是其精细的RGB 颜色控制能力。用户可以通过文本提示指定某个对象或区域的确切颜色值,模型能够严格遵循这些颜色指令,生成符合设计要求的图像。
- 精准颜色匹配:PGv3 可以在生成的图像中,对某些对象或区域应用用户指定的RGB值。这种精细的颜色控制允许设计师通过文本提示精确指定颜色,而不是依赖模型的默认调色板。
- 应用场景:这种精确的颜色控制在专业设计领域,如品牌设计、广告制作、产品包装设计中非常重要,允许设计师通过提示词直接控制生成图像中的颜色匹配。
 RGB 颜色控制的定性结果。由于空间限制,提示被省略,每个图像下方的颜色条表示提示中的指定项目和颜色。
RGB 颜色控制的定性结果。由于空间限制,提示被省略,每个图像下方的颜色条表示提示中的指定项目和颜色。
 RGB 颜色调色板控制的定性结果。PGv3 接受整体颜色调色板,自动将指定颜色应用于适当的对象和区域。
RGB 颜色调色板控制的定性结果。PGv3 接受整体颜色调色板,自动将指定颜色应用于适当的对象和区域。
3. 复杂文本渲染与排版能力
除了传统的图像生成,PGv3 在文本渲染方面展示了超强的能力,能够生成含有复杂文本内容的图像。这一能力特别适用于生成海报、广告、书籍封面等需要大量文本信息的设计任务。
- 多种文本风格支持:PGv3 能够生成符合提示的复杂文本内容,特别是在处理长文本提示时,模型能够确保文本的排版与布局符合设计要求。PGv3 能够根据提示生成多种文本风格,包括标语、广告文案、标题、描述性文本等。模型不仅可以生成图像,还可以确保文本与图像之间的排版合理。
- 准确的文本排版:文本在图像中的位置、字体、颜色、大小等都可以通过提示词进行控制,模型会严格遵循这些提示,确保生成的图像与用户需求一致。
- 例如,模型可以生成广告中复杂的文字内容,并且能够根据提示进行语言排版、字体选择和颜色控制。
 文本渲染的定性结果。PGv3 可以在各种类别中生成丰富的文本内容,从专业设计如广告和标志到有趣的创作如表情包和贺卡。
文本渲染的定性结果。PGv3 可以在各种类别中生成丰富的文本内容,从专业设计如广告和标志到有趣的创作如表情包和贺卡。
4. 多语言支持与生成能力
PGv3 拥有强大的多语言支持能力,可以处理和理解多种语言的文本提示,如英语、法语、俄语、西班牙语、葡萄牙语等,并生成符合这些语言提示的图像。
- 无需专门训练:在多语言评估中,PGv3 展示了卓越的语言理解和生成能力,即便没有对非英语数据进行专门训练,PGv3 依然能够处理来自多种语言的提示。这使得模型在国际化设计场景下表现优越,能够在不同语言文化环境下生成高质量的图像。
- 语言间的语义对齐:得益于 LLM 的多语言能力,PGv3 在多语言提示中依然能够保持高质量的文本与图像对齐,实现更广泛的应用场景支持。
 多语言定性结果,在每个面板中,图像是根据英语、西班牙语、菲律宾语、法语、葡萄牙语和俄语的提示生成的,排列顺序为从左上到右下。对于每个面板,我们展示使用的其中一种语言的提示,所有语言在面板中都有体现。
多语言定性结果,在每个面板中,图像是根据英语、西班牙语、菲律宾语、法语、葡萄牙语和俄语的提示生成的,排列顺序为从左上到右下。对于每个面板,我们展示使用的其中一种语言的提示,所有语言在面板中都有体现。
5. 复杂推理与场景理解能力
PGv3 的高级推理能力使其在处理复杂场景和多对象图像生成任务时表现突出,能够准确理解提示中的多个对象及其相互关系,并生成符合逻辑的图像。
- 对象关系处理:PGv3 能够处理多角色、多对象的复杂场景,包括对象的空间关系、相对位置和颜色匹配等。
- 场景理解:模型可以生成符合提示中描述的完整场景,从角色配置、背景细节到场景光影处理,都可以精准匹配提示内容。
 提示遵循的定性比较。用亮色突出显示的文本表示 Flux-pro 或 Ideogram-2 未能遵循提示的实例,而 PGv3 始终遵循提示中的所有细节。所示示例是我们评估提示集中的选定样本。
提示遵循的定性比较。用亮色突出显示的文本表示 Flux-pro 或 Ideogram-2 未能遵循提示的实例,而 PGv3 始终遵循提示中的所有细节。所示示例是我们评估提示集中的选定样本。
6. 高效的图像-文本对齐能力
PGv3 在图像与文本对齐方面表现优异,特别是在长文本提示或复杂描述的场景下,能够保持文本与生成图像之间的一致性。这在广告、产品设计、艺术创作等需要精确控制细节的应用中非常有用。
- DPG-bench 测试结果:在 DPG-bench 基准测试中,PGv3 展现了出色的文本对齐性能,能够处理复杂提示,并生成符合提示要求的图像内容。
- 多对象与多细节处理:模型能够准确处理含有多个对象、复杂细节和特定场景要求的文本提示,使其在高精度设计任务中有着广泛应用。
模型架构与创新点
- 深度融合架构 (Deep-Fusion Architecture):PGv3通过深度融合LLM与扩展的扩散模型 (Diffusion Model),创新性地将文本提示的理解深度嵌入到图像生成过程中。与传统依赖于T5或CLIP编码器的方式不同,PGv3完全依靠Llama3-8B模型在生成过程中的语言处理能力,以提高对复杂提示词的理解能力。
- 主要创新点:PGv3摒弃了常用的T5或CLIP文本编码器,直接从一个解码器式的LLM中提取文本条件输入。这使得模型在处理复杂的语言提示时具有更强的理解能力,并且与传统模型相比,能够生成更贴合文本内容的图像。
- 完整的信息流动:该模型利用了LLM中的所有层次信息,而不仅仅是提取最后一层的输出。通过这种方式,PGv3能够利用LLM的每一层隐含表示作为条件输入,实现更复杂的推理和生成过程。
- DiT架构与扩展:PGv3采用DiT(Diffusion Transformers)架构,模型中的每一个Transformer块与LLM的相应块完全对应,包括隐藏层维度、注意力头的数量和大小。这种设计允许图像生成模型与LLM的推理过程保持一致,最大化地利用了LLM的生成能力。
- 联合注意力机制:不同于传统的卷积网络扩散模型,PGv3采用了联合注意力机制,将图像特征与文本特征同时进行联合注意力计算。这减少了计算开销并提高了生成效率。
- 变分自编码器 (VAE) 改进:为了进一步提升图像细节生成的精确度,PGv3使用了一个16通道的变分自编码器(VAE),而不是常见的4通道。这使得模型在处理更高分辨率(512×512)图像时表现出色,特别是在生成小型物体和精细文字时效果显著提升。
- 多级别文本描述生成
内部图像描述生成器:PGv3 引入了一个内置的图像描述生成器,能够生成多个层次的图像描述。这些描述从非常详细的文本到概念化的总结都有,能够更好地适应不同场景下的文本提示生成需求。
-
- 多级别训练:为了增强模型的多样性,PGv3 在训练过程中对每张图像生成了多级别描述(如细节、概念、简要等)。通过随机抽取不同复杂度的描述进行训练,模型可以在处理不同提示时保持灵活性,同时避免数据过拟合。这种多级别的描述生成机制帮助模型建立了更好的语言概念层次,从而增强了模型对提示词的适应性。
- RGB颜色控制
精细的颜色控制:PGv3 引入了精确的 RGB 颜色控制机制,用户可以通过提示词精确指定图像中某个区域或对象的颜色值。相比于传统模型只能生成大致符合提示颜色的图像,PGv3 可以根据精确的 RGB 值生成符合设计要求的图像,因此特别适用于专业设计场景。
职徒简历,智能简历制作软件,基于GPT的简历优化和简历写作。