
MiniCPM3-4B 是 MiniCPM 开发的最新一代边缘端语言模型,其整体性能优于 Phi-3.5-mini-Instruct 和 GPT-3.5-Turbo-0125,并可与许多近期发布的7B~9B模型相媲美。与 MiniCPM1.0 和 MiniCPM2.0 相比,MiniCPM3-4B 功能更强大,应用范围更广泛,支持功能调用和代码解释功能。
此外,MiniCPM3-4B 配备了 32k 上下文窗口,并通过 LLMxMapReduce 技术,能够理论上处理无限上下文,而无需占用大量内存。
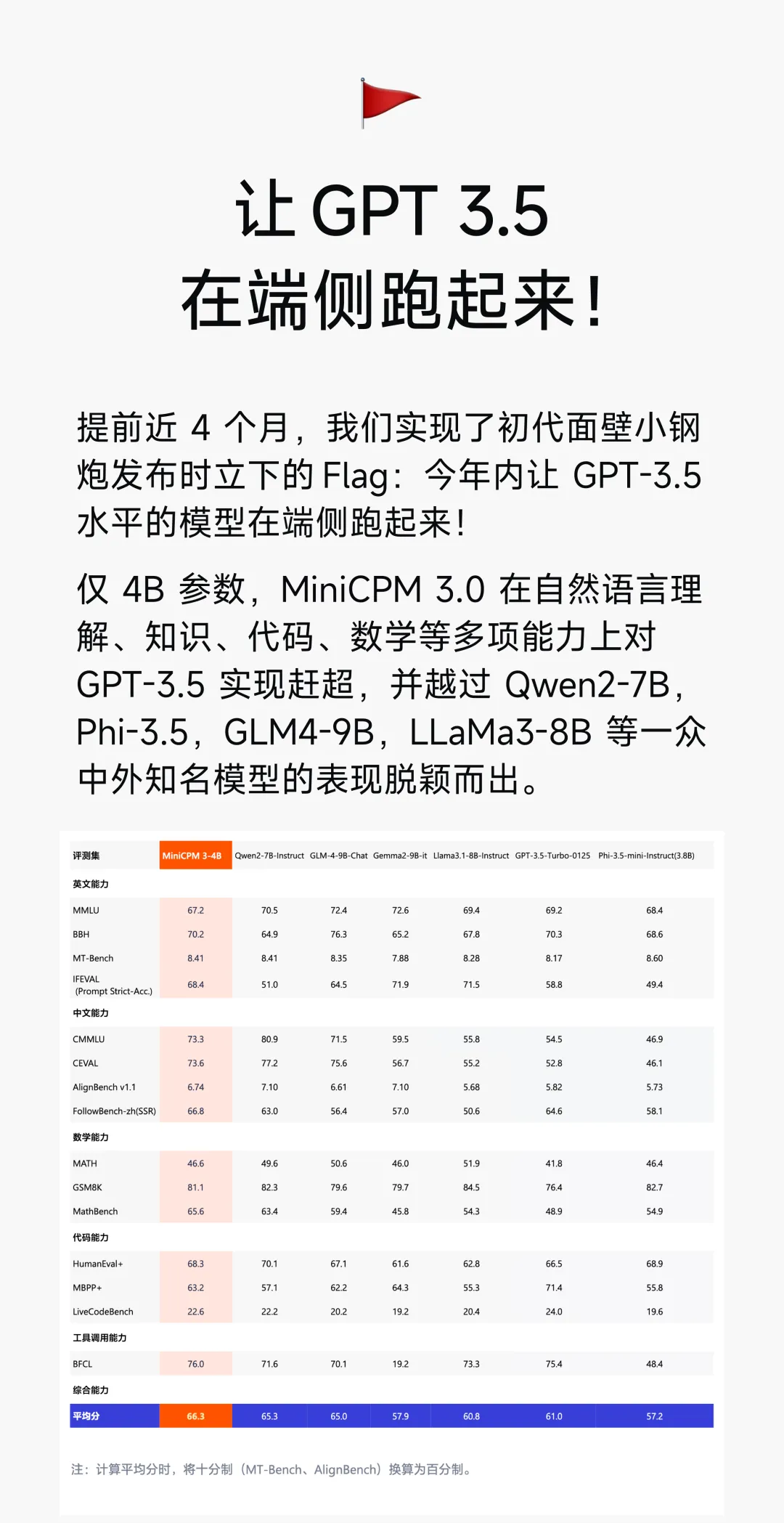
仅4B 参数,MiniCPM 3.0 在自然语言理解、知识、代码、数学等多项能力上对GPT-3.5 实现赶超,并越过 Qwen2-7B,Phi-3.5,GLM4-9B,LLaMa3-8B 等一众中外知名模型的表现脱颖而出。
MiniCPM3-4B 的主要优势
- 轻量级、性能强大:4B参数量模型的推理速度快,资源占用小,但性能不逊色于更大参数的模型。
- 多领域适应性强:在中英文任务、数学推理、代码生成和长文本处理等领域均表现出色。
- 丰富的功能扩展:支持工具调用、代码解释和检索增强生成,能够适应广泛的应用场景。
 主要功能特点
主要功能特点
- 参数量与性能对比MiniCPM3-4B 具有 40 亿参数,尽管模型参数量相对较小,但在多个任务上表现超越了更大规模的模型。具体对比如下:
- 超过 GPT-3.5-Turbo:在通用语言处理任务、数学推理、代码理解等方面,MiniCPM3-4B 在同等条件下性能优于 GPT-3.5-Turbo。
- 与 Llama3.1-8B-Instruct、Qwen2-7B-Instruct 相比:在中英文任务、长文本处理及工具调用能力等多个方面,MiniCPM3-4B 均表现不俗。
 2. 工具调用与代码解释器
2. 工具调用与代码解释器- 工具调用功能:MiniCPM3-4B 支持函数调用功能,并在 Berkeley Function Calling Leaderboard (BFCL) 上以 76.03% 的准确率取得 SOTA 成绩,超越了 Llama3.1-8B-Instruct、Qwen2-7B-Instruct 等模型。
- 代码解释器功能:支持代码解释器,能够执行 Python 等语言的代码,并生成实际的输出,如二维码生成等任务。
 3. 推理与语言能力
3. 推理与语言能力MiniCPM3-4B 在推理和语言能力上表现尤为突出:
- 数学能力:在 MathBench 任务中表现优异,超过了多个更大参数的模型如 GPT-3.5-Turbo 和 Llama3.1-8B。
- 中英文指令跟随能力:在英文任务 IFEval 中达到 68.4% 的准确率,中文任务 FollowBench-zh 中达到 66.8%,均超越 GLM-4-9B-Chat 和 Qwen2-7B-Instruct。
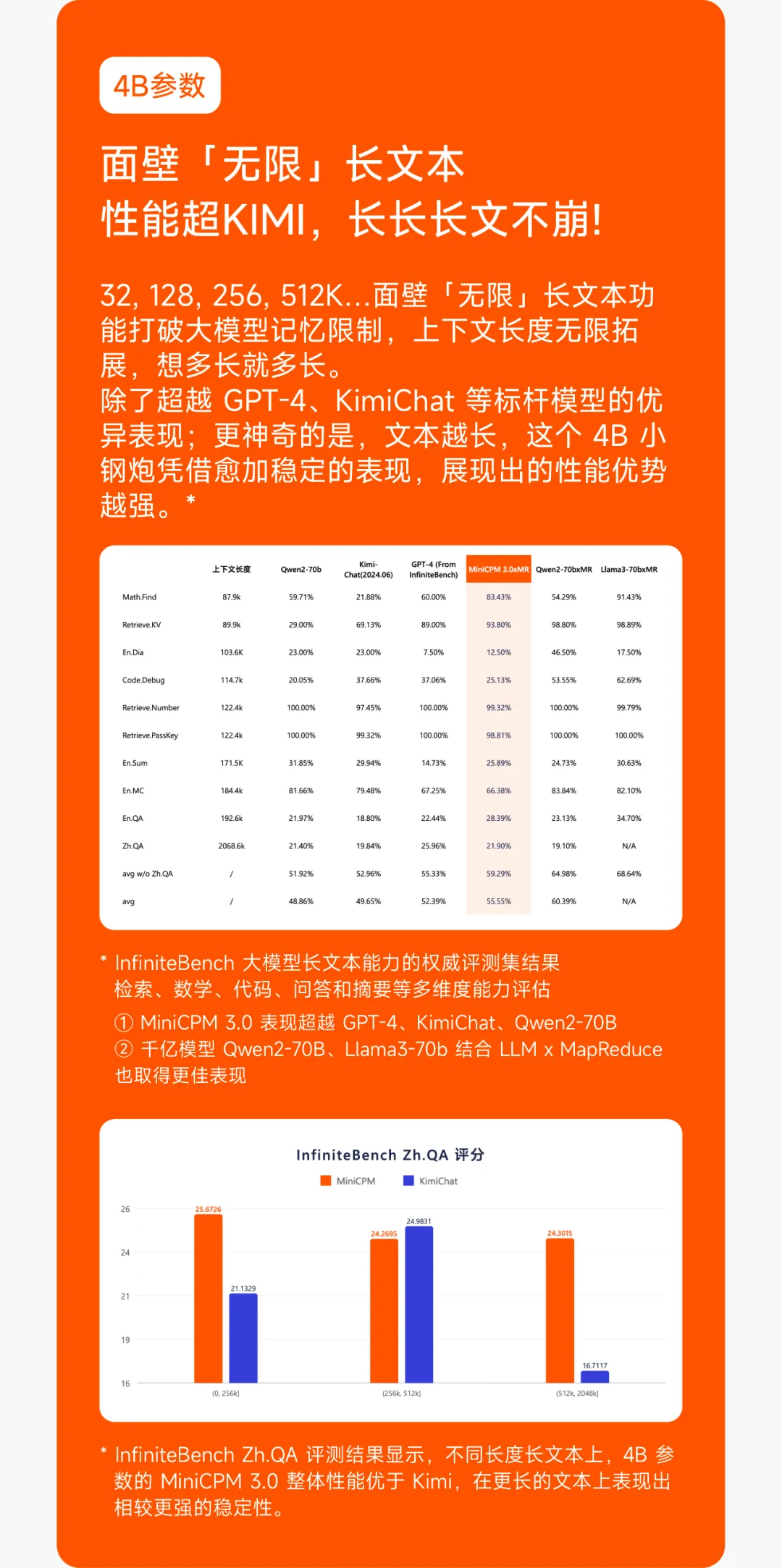
4. 长文本处理能力
- 32k 上下文支持:MiniCPM3-4B 原生支持 32k 的上下文长度,能够处理长篇文本并在大海捞针测试中表现出色。
- LLM x MapReduce 框架:提出了 LLM 与 MapReduce 的结合,理论上能够处理无限长度的上下文。
 5. RAG(检索增强生成)能力
5. RAG(检索增强生成)能力MiniCPM3-4B 还具有出色的检索增强生成(RAG)能力,能够在跨语言检索、开放域问答等任务中表现优异。发布的 RAG 套件包括 MiniCPM-Embedding 和 MiniCPM-Reranker,均在中文与跨语言的检索测试中取得了 SOTA 表现。
 6. 模型微调
6. 模型微调MiniCPM3-4B 支持通过 LoRA(低秩适配)进行模型微调,并可结合 LLaMA-Factory 进行进一步优化,以适应用户的具体需求。
🔗 https://github.com/OpenBMB/MiniCPM
365编辑器是一款拥有海量素材,版权图库,提供高效图文排版的内容编辑器。