
东京大学和Alternative Machine的研究人员开发了一种名为Alter3的仿人机器人系统,该系统可以直接将自然语言命令映射到机器人动作。通过利用大型语言模型(LLMs)如GPT-4,Alter3能够执行复杂的任务,如自拍或模仿幽灵。
- 在LLM出现之前,必须手动控制机器人所有的43个轴来模仿动作,这通常需要许多人工精细调整。现在,利用LLM,只需通过自然语言的指令,就可以实现复杂动作控制,无需迭代学习过程。
- 通过语言反馈,Alter3能够根据用户的语言指令调整运动代码,并将改进的动作存储在数据库中,形成有效的身体模式记忆。
- 通过在线平台Prolific招募了107名参与者,对九种不同的动作视频进行评估。结果显示,由GPT-4生成的动作得分显著高于对照组随机生成的动作,表明GPT-4能够准确地将语言表达映射到Alter3的身体上。
- Alter3能够在没有额外训练的情况下执行多种动作,展示了LLM数据集已经包含了动作描述。此外,Alter3还能够模仿鬼魂和动物,并通过面部表情和手势反映对话内容的情绪。该系统可应用于任何类人机器人,只需少量修改。
视频播放器
00:00
00:00
Alter3 的主要功能
- 自然语言到动作映射:Alter3 能够直接将自然语言命令转换为机器人动作。用户可以通过简单的语言指令控制机器人执行各种任务。
- 基于“代理框架”的动作规划:Alter3 使用GPT-4模型作为后台,通过“代理框架”来规划机器人执行任务的步骤。模型首先充当规划器,确定所需的动作步骤,然后由编码代理生成具体的机器人命令。
- 上下文学习与API适应:GPT-4 利用其上下文学习能力,适应并映射机器人的API命令。通过提供命令列表和使用示例,模型可以将任务步骤转换为API命令,发送给机器人执行。
- 人类反馈支持:Alter3 能够接收人类的反馈并据此调整动作。例如,当用户指示机器人“抬高手臂”时,反馈信息会被另一个GPT-4代理处理,调整相应的代码并更新动作序列。
- 多任务处理:Alter3 可以执行多种复杂任务,如自拍、喝茶、模仿幽灵或蛇等动作,还能在需要精细动作规划的场景中表现出色。
- 情感表达与模仿:GPT-4 的广泛知识库使其能够推断和表达情感。Alter3 能够通过身体动作反映出情感,如尴尬或喜悦,增强了人机互动的真实感。
- Alter3可以通过面部表情和肢体动作表达情感。即使文本中没有明确的情感表达,GPT-4也可以推断出合适的情感并反映在机器人的动作中。
- 示例:当听到一个有趣的故事时,表现出惊讶和愉悦的表情和动作。
- 零样本学习:
- 无需预训练:Alter3无需预训练即可根据语言指令生成新动作,这意味着不需要为每个新动作进行编程或训练。
- 使用现有数据:利用GPT-4的广泛训练数据集,这些数据包含了大量的动作描述,支持机器人生成多样化的动作。
- 广泛的应用场景:除了执行日常任务,Alter3 在需要高级动作规划和情感表达的领域(如娱乐和客户服务)也具有广泛的应用潜力。
Alter3 的技术细节
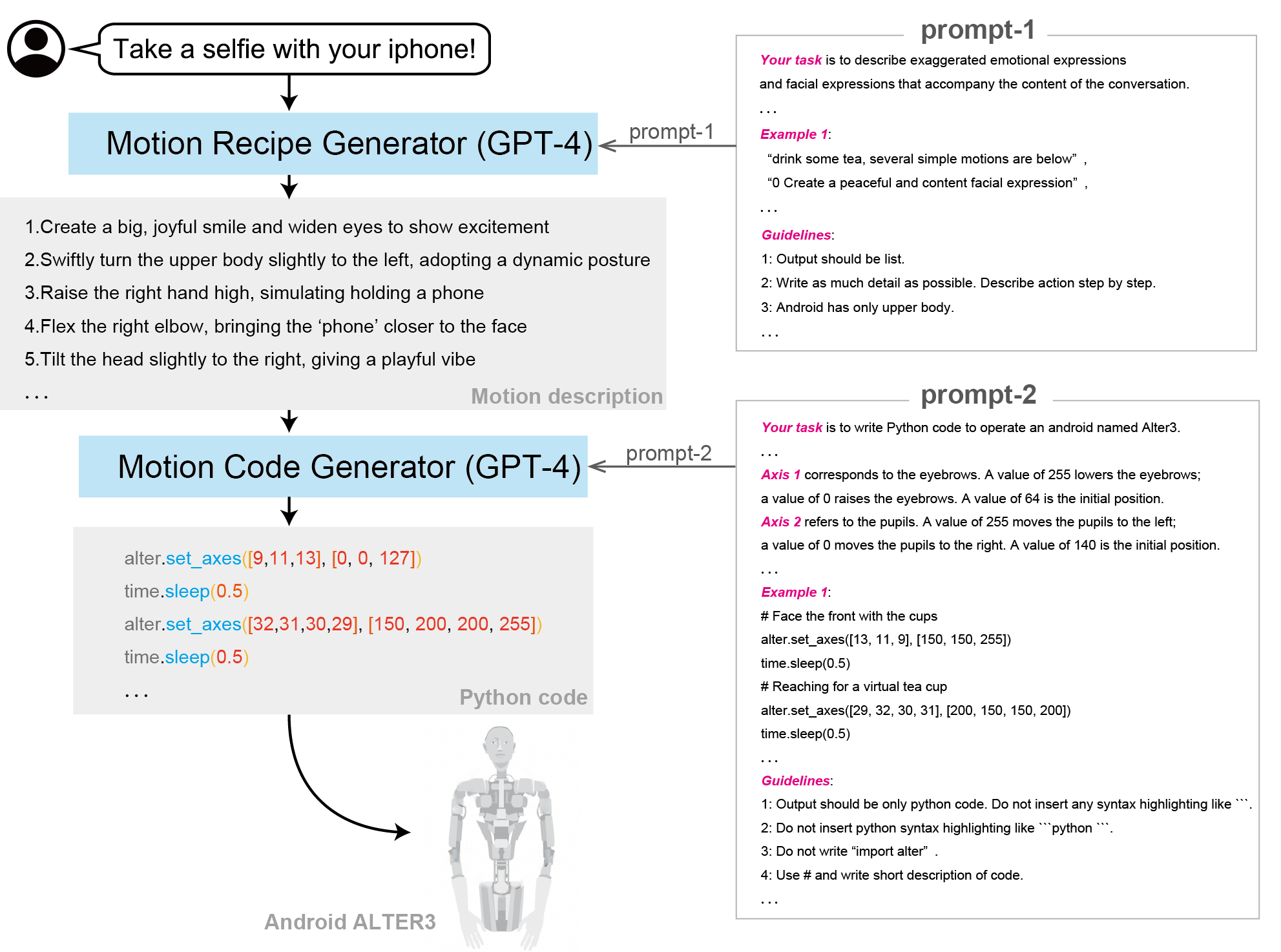
- 自然语言处理和映射
- 集成大语言模型:使用GPT-4作为核心语言模型,将其集成到Alter3机器人中。
- 语言到动作映射:Alter3 使用GPT-4模型来处理自然语言命令,将其映射到具体的机器人动作。通过大型语言模型,机器人能够理解和执行复杂的语言指令。
- 代理框架
- 描述:采用“代理框架”进行动作规划。框架分为两个阶段:首先是规划阶段,GPT-4确定执行任务所需的步骤;然后是编码阶段,生成具体的API命令。
- 规划器:在第一阶段,GPT-4模型作为规划器,分析自然语言指令,制定详细的动作计划。
- 编码代理:在第二阶段,编码代理负责将动作计划转换为机器人的API命令。
- 动作生成协议:
- 自然语言协议:使用自然语言协议(如Chain of Thought, CoT)生成控制机器人的Python代码,从而实现动作生成。
- 多样性生成:由于GPT-4具有非确定性,即使相同的输入也能生成不同的动作模式,增加了动作生成的多样性。
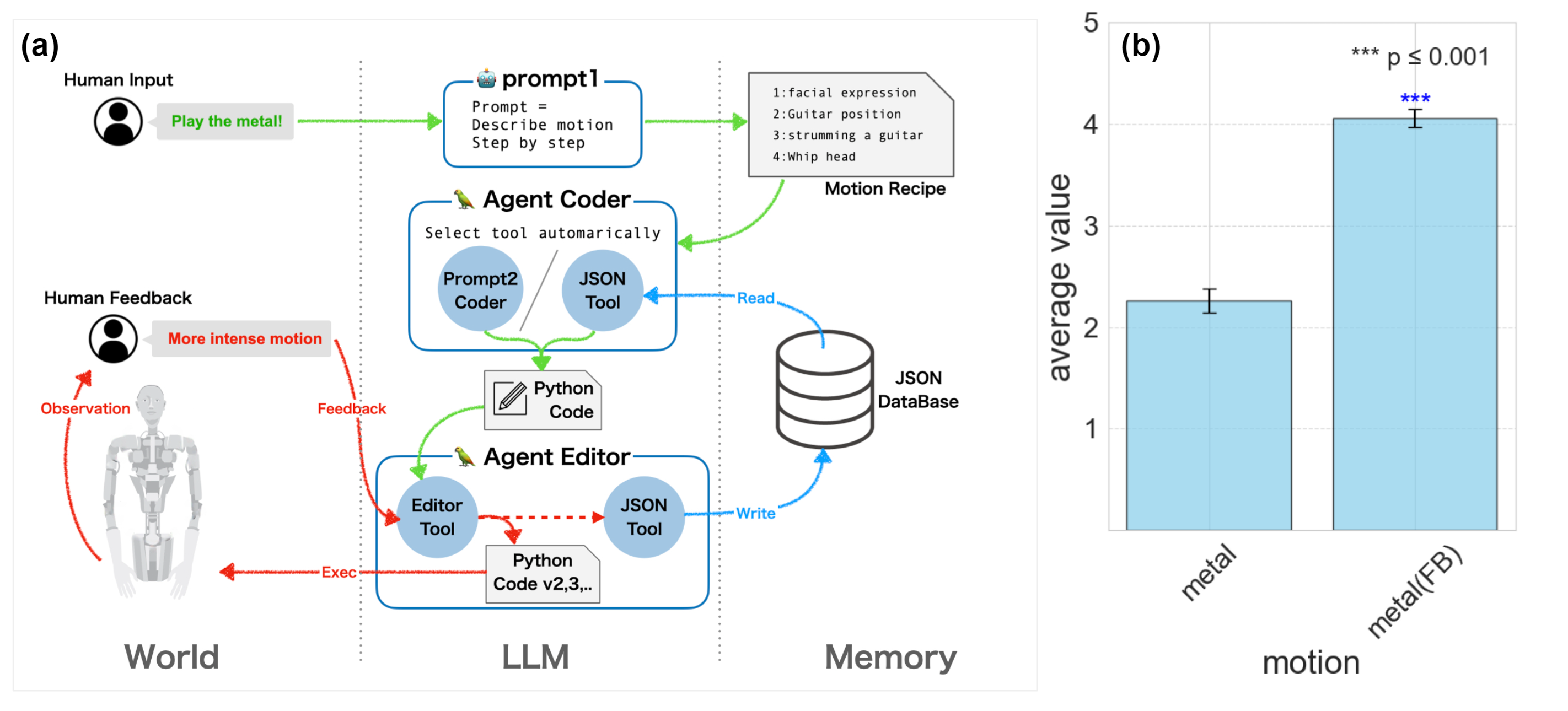
- 语言反馈系统:
- 即时调整:用户通过语言指令(如“手举高一点”)对动作进行即时调整,机器人根据反馈修改动作代码。
- 动作存储:改进后的动作被存储在JSON数据库中,带有描述性标签(如“举着吉他”),以便未来检索和使用。
- 上下文学习
- 描述:GPT-4 使用上下文学习能力适应机器人的API。通过提供命令列表和示例,模型能够将动作步骤映射到API命令。
- 例子和命令列表:在上下文中包含示例命令和解释,以帮助模型生成准确的API命令。
- 人类反馈和调整
- 描述:支持人类反馈,允许用户微调机器人的动作。反馈通过另一个GPT-4代理处理,调整动作代码并更新执行序列。
- 反馈处理:用户反馈如“抬高手臂”被处理并转化为代码调整,存储在数据库中以供未来使用。
- 情感表达
- 描述:GPT-4 的知识库支持情感推断和表达。Alter3 能够通过身体动作反映情感,如尴尬和喜悦。
- 情感推断:即使在没有明确情感表达的文本中,模型也能推断出合适的情感,并在机器人的物理响应中体现。
- 多任务处理和应用
- 描述:Alter3 能执行多种任务,如自拍、喝茶、模仿幽灵或蛇等动作,展示其在日常任务和复杂场景中的应用潜力。
- 任务示例:模型通过实验测试执行各种任务,如自拍和模仿动作。
- 外部存储与记忆:
- 外部记忆集成:通过语言反馈系统,Alter3能够将动作改进信息存储在外部记忆中,这些记忆在未来生成动作时被引用。
- 身体模式:这种外部记忆有效地充当Alter3的身体模式,使其能够不断学习和改进动作表现。
- 数据和模型训练
- 描述:GPT-4 的训练包括广泛的语言表示和动作描述,支持其在机器人控制中的应用。基础模型的知识库提供了丰富的背景知识,提升了机器人的任务执行能力。
- 基础挑战:尽管模型在高层次规划中表现出色,机器人在执行基本任务(如抓取物体、保持平衡、移动)方面仍面临挑战。
评估与结果
- 动作生成评估:
- 评估方法:使用视频展示九种不同生成动作,参与者通过观看视频对机器人动作的表达能力进行评分。
- 评分标准:采用5分制评分,1分为最差,5分为最好。
- 参与者招募:
- 招募平台:通过Prolific平台招募了107名参与者。
- 参与者任务:参与者观看视频并评估动作的表现力。
- 视频分类:
- 即时手势动作:包括自拍、喝茶、假装成为鬼魂、假装成为蛇等日常和模仿动作。
- 持续动作情景:包括复杂情景,如在电影院吃错别人的爆米花,或在公园跑步时感受古老生存故事的情感场景。
- 对照组设置:
- 随机动作:使用随机生成的动作作为对照组,动作标签由GPT-4生成。
- 对照视频:在参与者观看的视频中,插入三个随机动作对照视频。
- 统计分析:
- Friedman测试:用于比较不同视频评分的显著性差异,结果显示视频评分之间存在显著差异。
- Nemenyi测试:进一步分析显示,对照组视频与其他视频相比,评分差异显著(p值小于或等于0.001)。
- 结果总结:
- 评分结果:GPT-4生成的动作评分显著高于随机动作对照组,表明GPT-4生成的动作在表现力上更具优势。
- 动作多样性:GPT-4能够生成从日常动作到复杂情景的多样化动作,并能够表达情感,如尴尬和快乐。
- 情感表达:通过GPT-4,Alter3能够理解并反映对话内容中的情感,即使情感未明确表达,也能推断并在动作中体现。
主要评估结果总结
通过将GPT-4集成到Alter3机器人中,实现了零样本学习、自发动作生成和语言反馈优化,显著提升了机器人的表现力和自然度。Alter3能够表达情感并生成多样化的动作,展示了大型语言模型在机器人技术中的巨大潜力和广泛应用前景。这一研究不仅为机器人技术的发展提供了新的思路,也为未来更自然、更人性化的人机交互奠定了基础。
结论
- 零样本学习能力:
- 无需预训练:Alter3能够在无需特定编程或训练的情况下,通过GPT-4生成自然且多样化的动作。这表明GPT-4的训练数据集已经包含了丰富的动作描述,支持机器人直接生成复杂的动作。
- 语言反馈优化:
- 即时调整:通过语言反馈系统,用户能够即时调整和改进Alter3的动作。这种反馈机制允许机器人不断学习和优化其动作表现,增强了与人类的互动体验。
- 情感表达:
- 丰富的情感表现:Alter3不仅能够模仿人类的日常动作,还能通过面部表情和肢体动作表达情感。无论是直接表达还是从上下文中推断情感,Alter3都能通过GPT-4准确反映情感状态。
- 广泛应用潜力:
- 普适性:该系统可以应用于任何仿人机器人,只需进行小幅修改即可实现。这种通用性使其在各种机器人应用中具有广泛的潜力。
- 研究发现:
- 显著优势:评估结果表明,通过GPT-4生成的动作在表现力和自然度上显著优于随机生成的动作,展示了大型语言模型在机器人动作生成中的强大能力。
- 复杂场景模拟:Alter3能够生成从简单日常动作到复杂情景模拟的多样化动作,展示了其在机器人控制和人机交互中的广泛应用前景。
一些案例:
视频播放器
00:00
00:00
“装鬼 “的动作
视频播放器
00:00
00:00
表达尴尬的感觉
I was enjoying a movie while eating popcorn at the theater when I realized that I was actually eating the popcorn of the person next to me.
我在影院边吃爆米花边欣赏电影时,发现自己其实是在吃旁边人的爆米花。
视频播放器
00:00
00:00
用手机自拍
视频播放器
00:00
00:00
“暗投球 “的动作
视频播放器
00:00
00:00
“扮蛇 “的动作
视频播放器
00:00
00:00
ALTER3 能否再现故事?
视频播放器
00:00
00:00
“喝茶 “的动作
视频播放器
00:00
00:00
“弹吉他 “的动作
最好的 Sora 提示集成网站,UseSora.net官网入口网址