Llama3-V 是基于 Llama3 的多模态模型,能够处理图像输入并生成对应的文本描述,适用于多种多模态任务。该模型以不到500美元的成本构建,性能比现有的开源多模态理解模型 LLaVA 高出10-20%,在多项指标上与规模大100倍的闭源模型(如 GPT-4V)表现相当。
模型架构
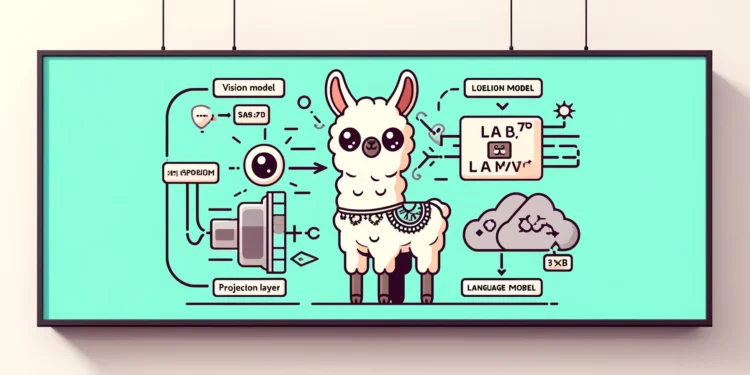
Llama3-V 的架构结合了视觉模型和语言模型,基于图像嵌入模型 (SigLIP)和Llama 3 8B模型。
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
一个支持中文搜索的高品质、开源、免费的矢量图标库。利用 ChatGPT API将Iconify 的21万个图标名做翻译并扩展成中文的关键词,使用户能以中文搜索到想要的图标。