
由于东南亚(SEA)地区语言多种多样,大多数现有的模型无法满足该地区需求。
Sailor基于Qwen 1.5训练开发,覆盖7种语言(包括印尼语、泰语、越南语、马来语、老挝语、英语和中文)
有4种不同大小的版本(0.5B、1.8B、4B和7B),支持不同的需求。

主要功能特点
- 多语言支持:专注于东南亚语言,包括印尼语、泰语、越南语、马来语和老挝语,以及英语和中文,覆盖SEA地区的多样化语言环境。
- 不同模型大小:提供从0.5B到7B不同大小的模型版本,以满足从轻量级到高性能的不同计算和应用需求。
- 高性能:在SEA语言的问答、常识推理、阅读理解等任务上表现出色,通过基准测试展示了其在多种任务上的强大性能。
- 开放使用:模型对研究和商业用途开放,无限制使用,但需遵守Qwen 1.5许可证。
训练方法
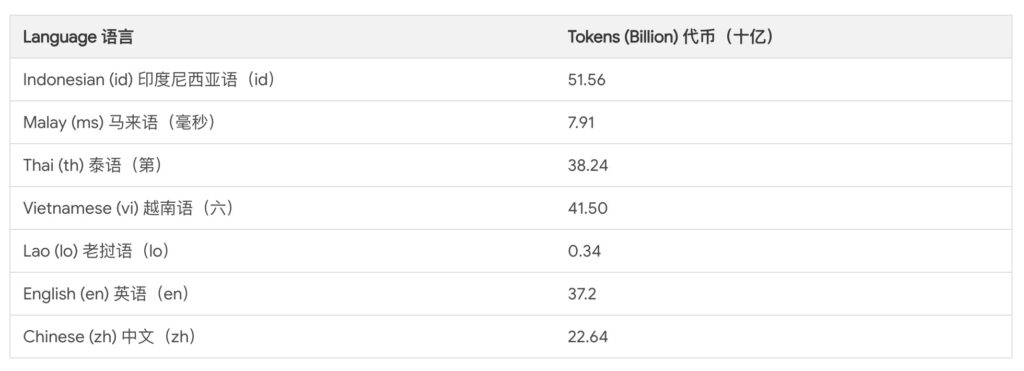
- 持续预训练:Sailor模型基于Qwen 1.5模型进一步进行了持续预训练,涵盖了200亿到400亿个标记,包括印尼语、泰语、越南语、马来语、老挝语、英语和中文七种语言,以适应东南亚多样化的语言环境。
- 数据策划和清理:训练语料库大量利用了公开可用的语料库,如SlimPajama、SkyPile、CC100和MADLAD-400。通过积极的数据去重和仔细的数据清理,确保了高质量的数据集。
- 系统实验确定权重:通过系统实验来确定不同语言的权重,确保了模型在各个语言上都能获得良好的训练效果,同时保持对英语和中文的高水平支持。
性能基准测试结果
Sailor模型在多个高质量基准测试上进行了评估,包括问答、常识推理、阅读理解和考试等不同任务,展现了其在SEA语言上的强大性能。
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
一款极简、强大的免费 AI文生视频制作工具。Vispunk Motion可让您仅使用文字创建逼真的短视频。您可以使用它来制作短片或社交媒体视频。